
Du willst mit Deinen Seiten gute Platzierungen in den Suchergebnissen (SERPs) erreichen? Bevor das passieren kann, müssen sie zuerst von Suchmaschinen wie Google gecrawlt und indexiert werden. Google hat allerdings nur begrenzte Ressourcen und kann nicht jede Seite im Internet indexieren. Und hier kommt das sogenannte Crawl Budget ins Spiel.
Das Crawl Budget ist die Menge an Zeit und Ressourcen, die Google in das Crawling und die Indexierung Deiner Website investiert. Dieses Crawl Budget deckt sich allerdings nicht unbedingt mit der Größe Deiner Website, was besonders bei umfangreichen Websites dazu führen kann, dass wichtige Inhalte von Google übersehen werden.
Die gute Nachricht: Es gibt Möglichkeiten, das verfügbare Crawl Budget für Deine Website zu erhöhen. Wie das funktioniert, werden wir in diesem Artikel ausführlich behandeln. Außerdem erklären wir Dir, wie Du Dein verfügbares Crawl Budget effizienter nutzen kannst, damit Google alle wichtigen Inhalte Deiner Website ohne Probleme findet und crawlt.
Bevor wir ans Eingemachte gehen, erklären wir Dir kurz einleitend, wie das Crawl Budget funktioniert und welche Websites ihr Crawl Budget optimieren sollten.
Wenn Du keine Lust auf Theorie hast, kannst Du den Part natürlich überspringen und direkt mit der Optimierung loslegen.
Table of Contents
- 1 Was ist das Crawl Budget?
- 2 Welche Rolle das Crawl Budget für Ranking und Indexierung spielt
- 3 Welche Websites ihr Crawl Budget optimieren sollten
- 4 So optimierst Du Dein Crawl Budget
- 5 So überwachst Du den Fortschritt Deiner Crawl-Budget-Optimierung
- 6 Optimiere Dein Crawl Budget für eine bessere SEO-Performance
Was ist das Crawl Budget?
Wie oben erwähnt, bezieht sich das Crawl Budget auf die Zeit und die Ressourcen, die Google in das Crawling Deiner Website steckt.
Allerdings ist das Crawl Budget kein statischer Wert. Laut Google Search Central spielen zwei wichtige Faktoren eine Rolle: Crawl Rate und Crawl Demand.
Crawl Rate
Die Crawl Rate sagt aus, wie viele Verbindungen der Googlebot gleichzeitig nutzen kann, um Deine Website zu crawlen.
Diese Zahl kann variieren, je nachdem, wie schnell Dein Server auf Anfragen von Google reagiert. Wenn Du einen leistungsstarken Server hast, der die Anfragen gut bewältigen kann, kann Google die Crawl Rate erhöhen und mehr Seiten Deiner Website auf einmal crawlen.
Wenn Deine Website jedoch zu lange benötigt, um die angefragten Inhalte zu liefern, drosselt Google die Crawl Rate. So soll vermieden werden, dass Dein Server überlastet wird und die User, die gerade auf Deiner Website unterwegs sind, darunter leiden müssen. Es kann also sein, dass einige Deiner Seiten nicht gecrawlt werden oder eine niedrigere Priorität erhalten.
Crawl Demand
Während sich die Crawl Rate darauf bezieht, wie viele Seiten Deiner Website Google crawlen kann, spiegelt der Crawl Demand wider, wie viel Zeit Google in das Crawlen Deiner Website investieren will. Der Crawl Demand erhöht sich durch:
- Hochwertigen Content: Aktuelle, wertvolle Inhalte, die gut bei den Nutzern ankommen.
- Beliebtheit der Website: Hoher Traffic und starke Backlinks deuten auf eine hohe Autorität und Relevanz der Website hin.
- Content-Updates: Regelmäßige Aktualisierungen der Inhalte sind ein Zeichen dafür, dass Deine Website dynamisch ist, was Google dazu ermutigt, sie häufiger zu crawlen.
Wir können also auf Basis von Crawl Rate und Crawl Demand sagen, dass das Crawl Budget die Anzahl der URLs repräsentiert, die Googlebot (technisch) crawlen kann und (inhaltlich) crawlen will.
Welche Rolle das Crawl Budget für Ranking und Indexierung spielt
Um in den Suchergebnissen angezeigt werden zu können, müssen Seiten zunächst gecrawlt und indexiert werden. Beim Crawling analysiert Google Inhalte und andere wichtige Elemente (Metadaten, strukturierte Daten, Verlinkungen usw.), um ein besseres Verständnis über die Seite zu gewinnen. Und diese Informationen werden dann zur Indexierung und fürs Ranking genutzt.
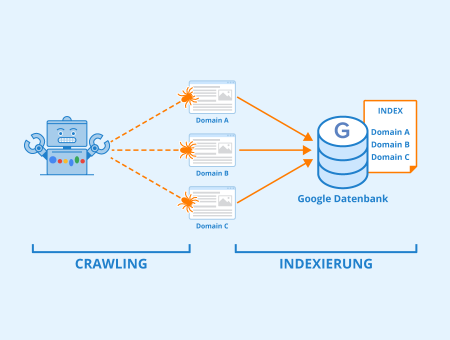
Abbildung: Indexierung – Autor: Seobility – Lizenz: CC BY-SA 4.0
Wenn Dein Crawl Budget aufgebraucht ist, können Suchmaschinen wie Google Deine Seiten nicht mehr vollständig crawlen. Das heißt, es dauert länger, bis die Seiten verarbeitet und dem Suchindex hinzugefügt werden. Deine Inhalte erscheinen deshalb nicht so schnell in den Suchergebnissen, wie sie sollten, und es kann passieren, dass User bei der Online-Suche Deine Inhalte nicht finden. Worst Case: Google findet möglicherweise einige Deiner wertvollsten Seiten nie.
Ein erschöpftes Crawl Budget kann auch zu „fehlendem Content“ führen, nämlich wenn Google Deine Website nur teilweise crawlt oder indexiert und dabei Text, Links oder Bilder auslässt. Das hat zur Folge, dass Google Deine Seiten anders bewertet, als sie es verdient haben. Und das kann Dein Ranking beeinträchtigen.
Wir möchten an dieser Stelle aber klarstellen, dass das Crawl Budget kein Rankingfaktor ist. Es hat ausschließlich Einfluss auf die Qualität des Crawlings und auf die Zeit, die in die Indexierung Deiner Seiten investiert wird, um in den SERPs zu ranken.
Welche Websites ihr Crawl Budget optimieren sollten
Im Google Search Central Guide erwähnt Google, dass besonders die folgenden Websites von Problemen mit dem Crawl Budget betroffen sein können:
- Websites mit sehr vielen Seiten (= mehr als 1 Million Seiten), die regelmäßig aktualisiert werden
- Websites mit einer mittleren bis großen Anzahl von Seiten (= mehr als 10.000 Seiten), die sehr häufig aktualisiert werden (täglich)
- Websites mit einem großen Anteil an Seiten, die in der Google Search Console als „Gecrawlt – zurzeit nicht indexiert“ angezeigt werden, was auf ineffizientes Crawling hindeutet*
*Tipp: Bei Seobility kannst Du sehen, ob es eine große Diskrepanz zwischen den gecrawlten und den tatsächlich indexierbaren Seiten gibt, also, ob ein Großteil des Crawl Budgets für Deine Website verschwendet wird. Ist das der Fall, wird in Deinem Technik & Meta Dashboard eine Warnung angezeigt:
Es wurden nur X Seiten gefunden, die als relevant eingestuft werden können.
Sollte Deine Website keiner der oben genannten Kategorien entsprechen, sollte ein erschöpftes Crawl Budget jedoch eher unwahrscheinlich sein.
Mit einer Ausnahme: Wenn Deine Website viele JavaScript-basierte Seiten hostet, solltest Du darüber nachdenken, sie zu optimieren, da die Verarbeitung von JS-Seiten ziemlich viele Ressourcen frisst.
Warum JavaScript-Crawling das Crawl Budget Deiner Website erschöpft
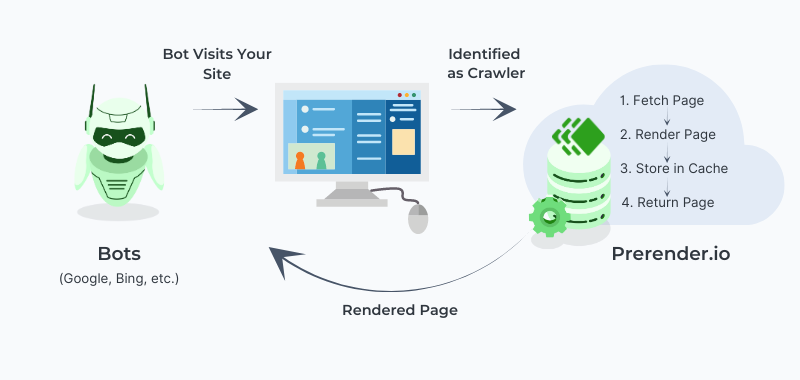
Wenn Google einfache HTML-Seiten indexiert, sind lediglich zwei Schritte nötig: Crawlen und Indexieren. Bei dynamischen, auf JavaScript basierenden Inhalten braucht Google allerdings drei Schritte: Crawlen, Rendern und Indexieren. Der Vorgang erfolgt also quasi in zwei Etappen, wie Du in der Abbildung unten sehen kannst.
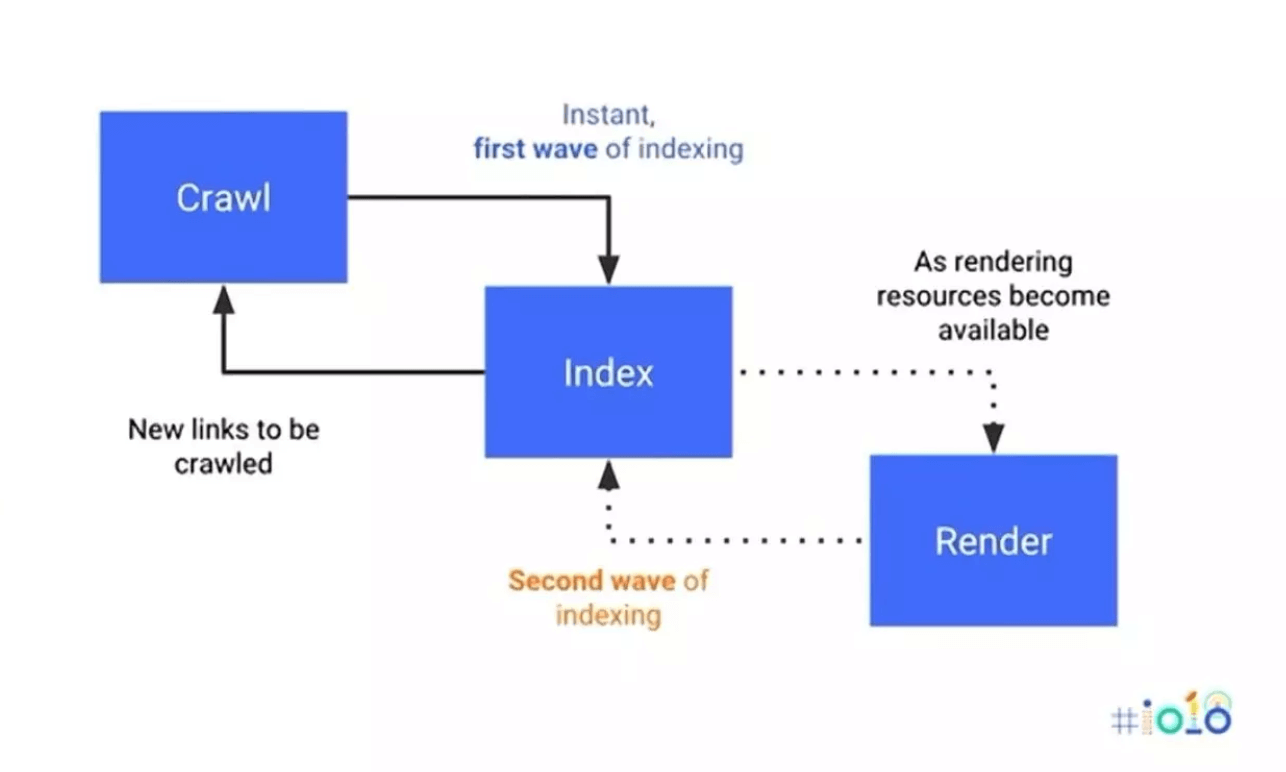
Quelle: Search Engine Journal
Je langwieriger und komplexer dieser Prozess ist, desto mehr Crawl Budget wird verbraucht. Und durch den zusätzlichen Rendering-Schritt kann Dein Crawl Budget recht schnell erschöpft sein und zu Problemen mit fehlenden Inhalten führen. Oftmals sind die nicht auf JavaScript basierenden Inhalte schon fertig indexiert, bevor die Indexierung der JavaScript-generierten Inhalte abgeschlossen ist. Dadurch kann es passieren, dass Google beim Ranking der Seite unvollständige Informationen heranzieht und den teilweise oder noch ganz ungecrawlten JavaScript-Inhalt komplett ignoriert.
Außerdem kann der zusätzliche Rendering-Schritt den Zeitaufwand für die Indexierung erheblich erhöhen. Konkret heißt das, dass die Seite erst nach Tagen, Wochen oder sogar Monaten in den Suchergebnissen angezeigt wird.
Wir erklären Dir an späterer Stelle, wie Du Probleme mit dem Crawl Budget speziell für JavaScript-lastige Seiten in den Griff bekommen kannst. Fürs Erste reicht es zu wissen, dass Crawl Budget ein Thema sein könnte, wenn Deine Seite viele JavaScript-basierte Inhalte enthält.
Schauen wir uns jetzt genauer an, welche Möglichkeiten Dir generell zur Verfügung stehen, um das Crawl Budget Deiner Website zu optimieren!
So optimierst Du Dein Crawl Budget
Das Ziel einer Crawl-Budget-Optimierung ist es, Google dazu zu bewegen, Deine Seiten bestmöglich zu crawlen. Die Optimierung soll dafür sorgen, dass Seiten schnell indexiert und in den Suchergebnissen angezeigt werden, und zwar ohne dass dabei wichtige Seiten übersehen werden.
Um das zu erreichen, stehen Dir zwei grundlegende Mechanismen zur Verfügung:
- Erhöhung des Crawl Budgets: Optimiere die Faktoren, die die Crawl Rate und den Crawl Demand Deiner Website steigern könnten. Dazu gehören zum Beispiel die Server-Performance, die Beliebtheit Deiner Website, die Qualität Deiner Inhalte und deren Aktualität.
- Optimale Nutzung des bestehenden Crawl Budgets: Verhindere, dass der Googlebot irrelevante Seiten Deiner Website crawlt. Lenke ihn stattdessen auf wichtige, wertvolle Inhalte. So findet Google schneller Deine besten Inhalte, was wiederum den Crawl Demand erhöhen kann.
Sehen wir uns jetzt einige Optimierungsstrategien für beide Mechanismen an.
Fünf Möglichkeiten, das meiste aus Deinem bestehenden Crawl Budget herauszuholen
1. Schließe minderwertige Inhalte vom Crawling aus
Wenn eine Suchmaschine minderwertige Inhalte crawlt, wird Dein kostbares Crawl Budget verschwendet, ohne dass Du etwas davon hast. Seiten mit geringem Wert sind zum Beispiel Log-in-Seiten, Warenkörbe oder Deine Datenschutzrichtlinie. Solche Seiten sollten in der Regel nicht in den Suchergebnissen ranken. Und deshalb sollte Google sie auch nicht crawlen.
Es mag vielleicht kein riesiges Problem sein, wenn Google beim Crawling einige solcher Seiten erwischt. Es gibt jedoch Fälle, in denen eine große Anzahl solcher Seiten automatisch und unkontrolliert erstellt wird und hier solltest Du auf jeden Fall einschreiten.
Ein Beispiel dafür sind sogenannte Infinite Spaces. Diese Bereiche einer Website können eine unendliche Anzahl an URLs generieren. Das ist typischerweise bei dynamischem Inhalt der Fall, der sich an das Verhalten von Usern anpasst. Konkrete Beispiele sind Kalender (z. B. jedes mögliche Datum), Suchfilter (z. B. unendliche Kombinationen von Filtern und Sortierungen) oder nutzergenerierte Inhalte (z. B. Kommentare).
Beispiel: Ein Kalender mit einem Link zum nächsten Monat kann zur Folge haben, dass Google diesem Link unendlich folgt:
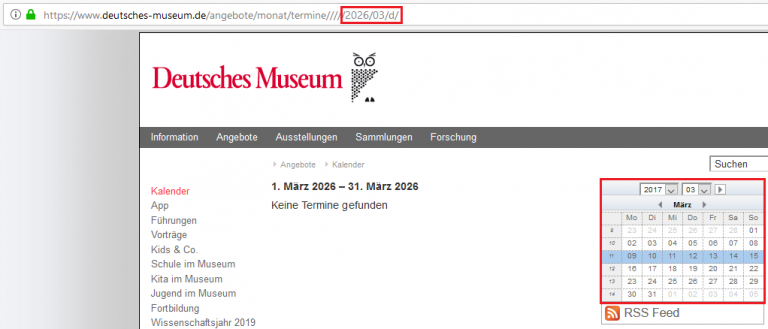
Screenshot von deutsches-museum.de
Wie in dem Beispiel zu erkennen ist, generiert jeder Klick auf den rechten Pfeil eine neue URL. Es kann passieren, dass Google diesem Link endlos folgt, sodass eine riesige Masse an URLs entsteht, die Google einzeln abrufen müsste.
Empfohlene Lösung: robots.txt oder nofollow
Du kannst Googlebot relativ einfach davon abhalten, Infinite Spaces zu folgen, indem Du diese Bereiche Deiner Website mit der robots.txt-Datei vom Crawling ausschließt. Die robots.txt-Datei teilt Suchmaschinen mit, welche Bereiche Deiner Website sie crawlen dürfen und welche nicht.
Wenn Du zum Beispiel verhindern willst, dass Googlebot Deine Kalenderseiten crawlt, musst Du nur die folgende Anweisung in Deine robots.txt-Datei aufnehmen:
Disallow: /calendar/
Eine alternative Methode ist die Verwendung des Nofollow-Attributs für Links, die einen Infinite Space erzeugen können. Obwohl viele SEO-Experten davon abraten, nofollow für interne Links zu nutzen, ist das in diesem Fall mehr als in Ordnung.
Im Beispiel oben mit dem Kalender kannst Du nofollow für den „nächster Monat“-Link verwenden, um zu verhindern, dass Googlebot dem Link folgt und ihn crawlt.
2. Entferne Duplicate Content
Ähnlich wie bei Seiten mit geringem Wert bringt es Dir nichts, wenn Google Duplicate Content crawlt. Konkret sind das Seiten, auf denen identische oder sehr ähnliche Inhalte unter verschiedenen URLs angezeigt werden. Solche Seiten verschwenden die von Google bereitgestellten Ressourcen, weil die Suchmaschine sehr viele URLs crawlen muss, ohne dabei auf neue Inhalte zu stoßen.
Es gibt bestimmte technische Probleme, die zu einer großen Anzahl duplizierter Seiten führen können. Wenn Du Probleme mit Deinem Crawl Budget hast, solltest Du also unbedingt prüfen, ob so ein Problem vorliegen könnte. Ein Beispiel sind fehlende Weiterleitungen (Redirects) zwischen den www- und nicht-www-Versionen einer URL oder von HTTP zu HTTPS.
Duplicate Content durch fehlende Redirects
Wenn diese allgemeinen Redirects nicht korrekt eingerichtet sind, kann sich die Anzahl der crawlbaren URLs verdoppeln oder sogar vervierfachen. Zum Beispiel könnte die Seite www.example.com ohne Redirect unter vier verschiedenen URLs verfügbar sein, nämlich:
http://www.example.com
https://www.example.com
http://example.com
https://example.com
Und damit tust Du dem Crawl Budget Deiner Website wirklich keinen Gefallen.
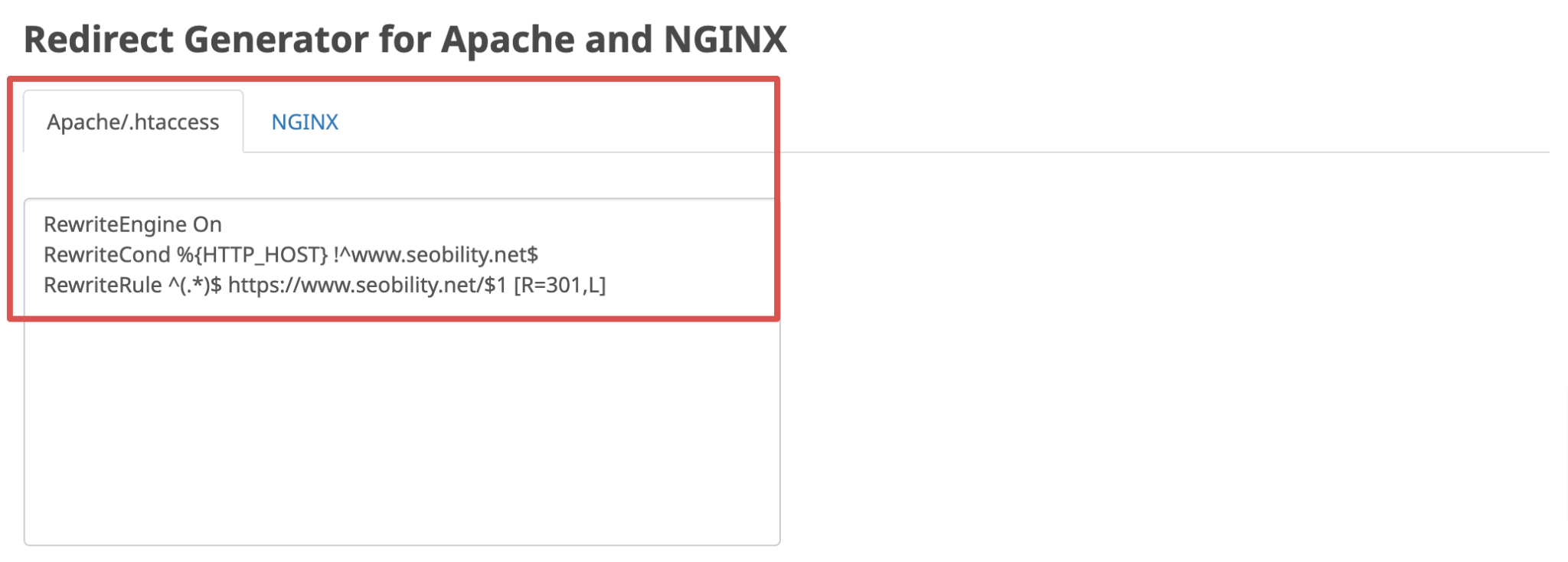
Empfohlene Lösung: Überprüfe Deine Redirects und fixe sie bei Bedarf
Mit dem kostenlosen Redirect Checker von Seobility kannst Du ganz einfach überprüfen, ob die WWW-Weiterleitungen Deiner Website korrekt konfiguriert sind. Gib einfach Deine Domain ein und wähle die URL-Version aus, zu der Deine User standardmäßig weitergeleitet werden sollen.
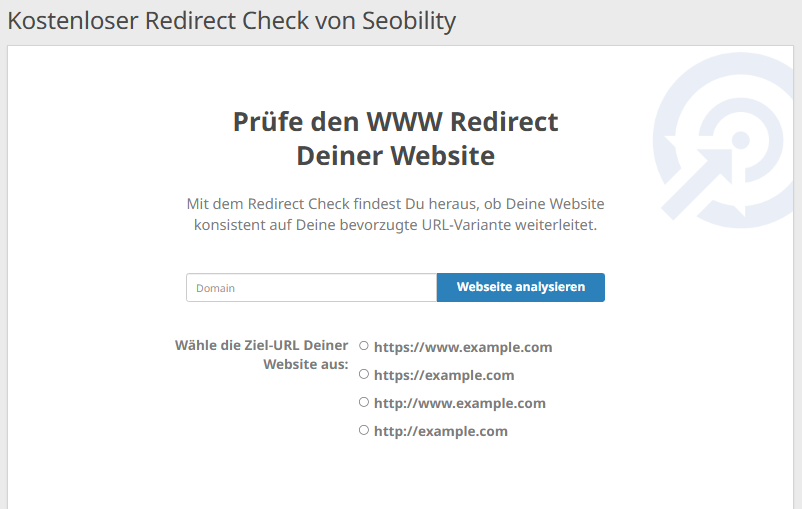
Falls das Tool Probleme findet, findest Du den korrekten Redirect-Code für Deinen Apache- oder NGINX-Server im Redirect Generator auf der Ergebnisseite. So kannst Du ganz einfach mit ein paar Klicks defekte oder fehlende Redirects und den dadurch entstandenen Duplicate Content korrigieren.
Duplicate Content durch URL-Parameter
Ein weiteres technisches Problem, das eine große Anzahl identischer Seiten zur Folge haben kann, sind URL-Parameter.
Viele eCommerce-Websites verwenden URL-Parameter, damit Besucher die Produkte einer Kategorieseite nach verschiedenen Kriterien wie Preis, Relevanz oder Bewertungen sortieren können.
Beispielsweise kann eine eCommerce-Seite den Parameter ?sort=price_asc an die URL ihrer Produktübersichtsseite anhängen, um die Produkte, beginnend mit dem niedrigsten Preis, nach Preis zu sortieren:
www.abc.com/products?sort=price_asc
Dadurch entsteht eine neue URL, die dieselben Produkte wie die reguläre Seite enthält, nur in einer anderen Reihenfolge. Bei Websites mit vielen Kategorien und mehreren Sortieroptionen kann das leicht zu einer beträchtlichen Anzahl von doppelten Seiten führen, die das Crawl Budget verschwenden.
Ein ähnliches Problem tritt bei der sogenannten Faceted Navigation auf. Diese Art von Navigation wird häufig in Online-Shops eingesetzt. Dabei können die Ergebnisse für bestimmte Produktkategorien anhand von Kriterien wie Farbe oder Größe eingeschränkt werden. Hierfür werden URL-Parameter genutzt, wodurch viele neue URLs entstehen:
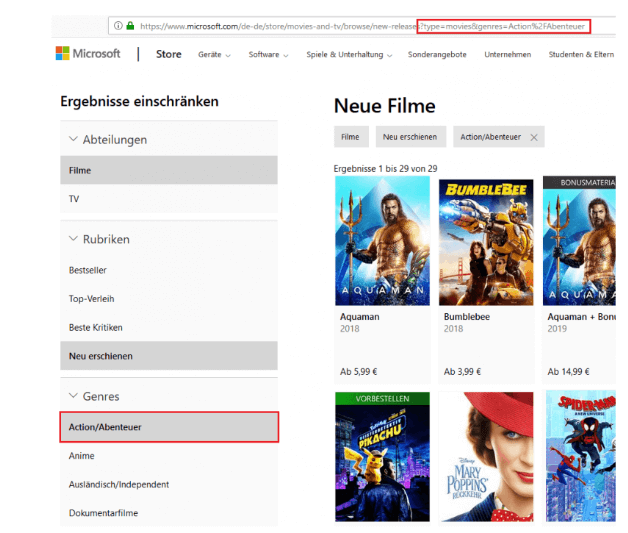
Screenshot von microsoft.com
In dem obigen Beispiel wird die Beschränkung der Ergebnisse auf das Genre „Action/Abenteuer“ durch den URL Parameter &genres=Action%2FAbenteuer umgesetzt. Dadurch entsteht eine neue URL, die das Crawl Budget unnötig beansprucht, da die Seite keinen neuen Inhalt liefert, sondern nur einen Ausschnitt der Seite ohne diese Einschränkung darstellt.
Empfohlene Lösung: robots.txt
Wie auch bei Seiten mit geringem Wert ist es am einfachsten, Googlebot durch die robots.txt-Datei vom Crawling solcher URLs abzuhalten. In den obigen Beispielen könnten wir die Parameter, die nicht von Google gecrawlt werden sollen, wie folgt ausschließen:
Disallow: /*?sort=
Disallow: /*&genres=Action%2FAdventure
Disallow: /*?genres=Action%2FAdventure
Dieser Ansatz ist die einfachste Methode, durch URL-Parameter verursachte Crawl Budget-Probleme zu lösen. Allerdings solltest Du dabei beachten, dass das nicht für jeden Fall die richtige Lösung ist. Wenn Seiten per robots.txt vom Crawling ausgeschlossen werden, bedeutet das nämlich auch, dass Google wichtige Meta Informationen wie Canonical Tags oder noindex Anweisungen nicht mehr finden und somit auch nicht berücksichtigen kann.
Wenn das Crawl Budget nicht Dein größtes Problem ist, ist eine andere Lösung zur Handhabung von Parametern und Faceted Navigation vielleicht besser geeignet.
Ausführliche Leitfäden zu beiden Strategien findest Du hier:
Wenn Du es vermeiden kannst, solltest Du generell eher auf URL-Parameter verzichten. Zum Beispiel ist es besser, Cookies zur Übertragung von Session-Informationen zu nutzen, als URL-Parameter mit Session-IDs.
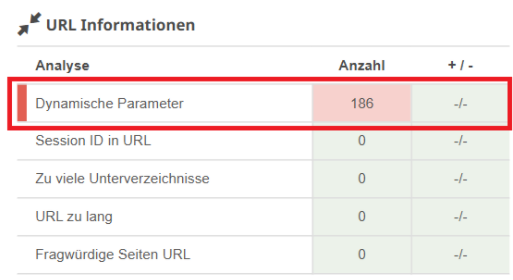
Tipp: Mit dem Website Audit-Tool von Seobility findest Du ganz einfach alle URLs mit Parametern auf Deiner Website.
Seobility > Onpage > Technik & Meta > URL Informationen
Du solltest jetzt ein gutes Verständnis dafür haben, was Du mit identischen Seiten oder Seiten mit geringem Wert machen kannst, um Dein Crawl Budget zu entlasten. Gehen wir also zur nächsten Strategie über!
3. Optimiere Ressourcen wie CSS- und JavaScript-Dateien
Wie bei HTML-Seiten muss auch jede CSS- und JavaScript-Datei auf Deiner Website von Google aufgerufen und gecrawlt werden, was einen Teil Deines Crawl Budgets verbraucht. Dieser Prozess erhöht dazu die Ladezeit der Seite. Das kann sich negativ auf Dein Ranking auswirken, denn der Pagespeed ist ein offizieller Google-Ranking-Faktor.
Empfohlene Lösung: Anzahl der Dateien minimieren und/oder eine Prerendering-Lösung implementieren
Halte die Anzahl der Dateien so gering wie möglich, indem Du Deinen CSS- oder JavaScript-Code in weniger Dateien zusammenfasst und optimiere bestehende Dateien, indem Du unnötigen Code entfernst.
Wenn Deine Website jedoch eine große Menge an JavaScript verwendet, reicht das möglicherweise nicht aus. In diesem Fall solltest Du überlegen, ob eine Prerendering-Lösung sinnvoll ist.
Beim Prerendering wird eine HTML-Version Deiner JavaScript-Inhalte erstellt, die dann direkt indexiert werden kann. Das macht die Indexierung schneller, was Dein Crawl Budget schont. Und Deine Inhalte und SEO-Elemente werden vollständig indexiert.
Prerender bietet eine Prerendering-Lösung an, die die Indexierungsgeschwindigkeit Deiner JavaScript-Website um bis zu 260 % beschleunigen kann.
Hier erfährst Du mehr über Prerendering und die Vorteile für die JavaScript-Optimierung Deiner Website.
4. Vermeide Links zu Redirects und Weiterleitungsschleifen
Wenn URL A auf URL B weiterleitet, muss Google zwei URLs von Deinem Webserver abrufen, um zum eigentlichen Inhalt zu gelangen, der gecrawlt werden soll. Und wenn Du auf Deiner Website viele Redirects hast, summiert sich das schnell und verbraucht Dein Crawl Budget.
Weiterleitungsschleifen sind noch ungünstiger: Sie entstehen, wenn es zwischen Seiten eine Endlosschleife gibt: Seite A > Seite B > Seite C > und zurück zu Seite A. Dabei hängt der Googlebot in einer Schleife fest und Dein wertvolles Crawl Budget löst sich schnell in Luft auf.
Empfohlene Lösung: Direkte Verlinkung auf die Ziel-URL und Vermeidung von Redirect-Ketten
Anstatt Google auf eine Seite zu schicken, die auf eine andere URL weiterleitet, solltest Du bei internen Links immer direkt auf die eigentliche Ziel-URL verlinken.
Praktischerweise zeigt Dir Seobility alle weiterleitenden Seiten auf Deiner Website an, sodass Du Verlinkungen auf weiterleitende Seiten leicht anpassen kannst:
Seobility > Onpage > Struktur > Verlinkungen
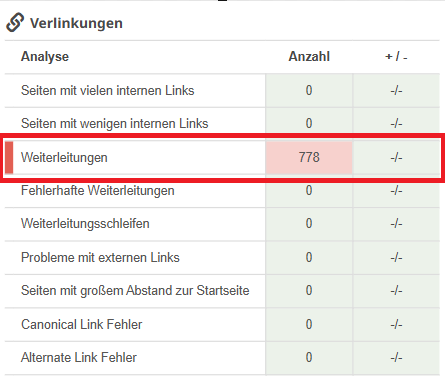
Und mit der Analyse “Weiterleitungsschleifen” erkennst Du auf einen Blick, ob es Seiten gibt, die Teil einer unendlichen Weiterleitungsschleife sind.
Seobility > Onpage > Struktur > Verlinkungen > Weiterleitungsschleifen
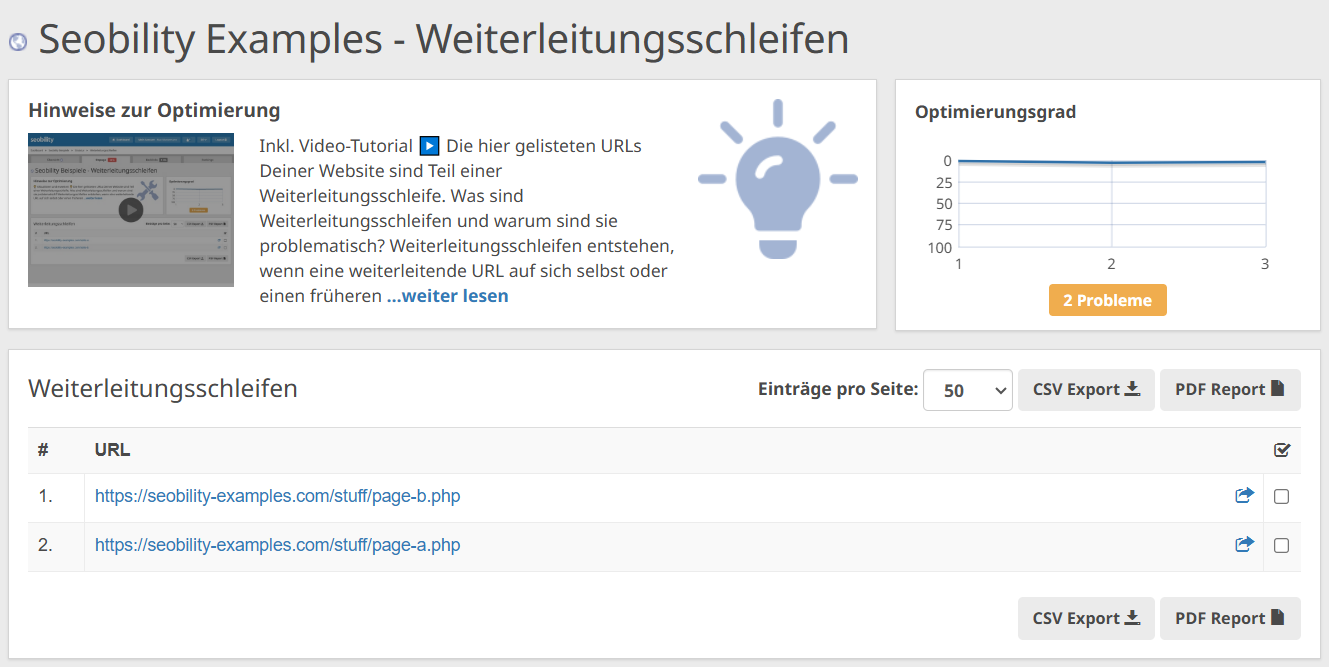
5. Vermeide Soft 404 Fehler
Seiten im Internet kommen und gehen. So kann es passieren, dass sowohl User als auch Google weiterhin versuchen, auf eine Seite zuzugreifen, die bereits gelöscht wurde. In diesem Fall sollte der Server mit einem „404 Not Found“ Statuscode antworten (was anzeigt, dass die Seite nicht existiert).
Allerdings kann es sein, dass der Server aus technischen Gründen (z. B. individuelle Fehlerhandhabung oder CMS-interne Systemeinstellungen) oder bei der Generierung dynamischer JS-Inhalte einen Statuscode 200 zurücksendet (damit wird angezeigt, dass die Seite existiert). Dies nennt man einen Soft 404-Fehler.
Dieser signalisiert Google, dass die Seite existiert. Sie wird so lange weiter gecrawlt, bis ein 404 Statuscode eingerichtet wird – was wertvolles Crawl Budget verschwendet.
Empfohlene Lösung: Kofiguriere Deinen Server, um einen korrekten Statuscode zurückzugeben
Google informiert Dich in der Search Console über Soft 404-Fehler auf Deiner Website:
Google Search Console > Seitenindexierung > Soft 404
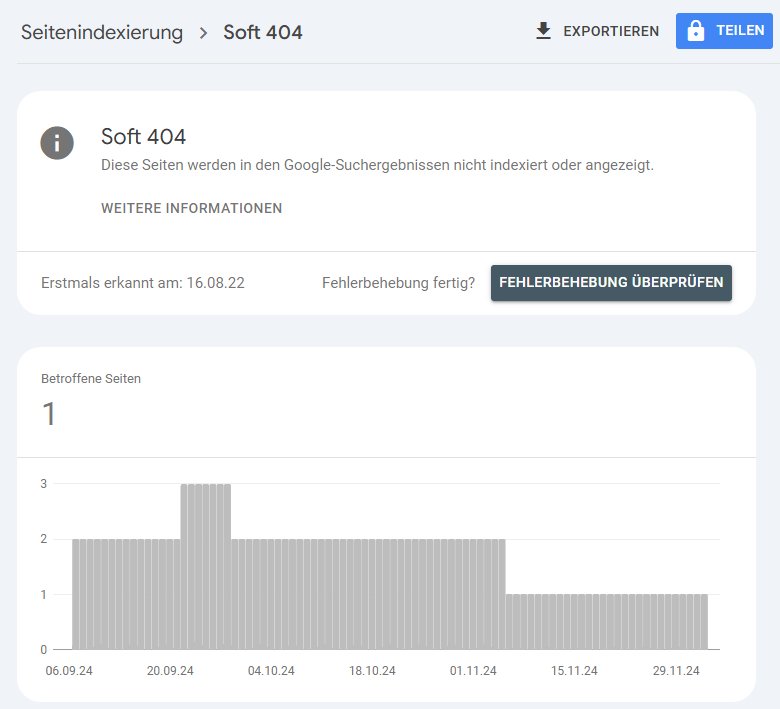
Zur Behebung von Soft 404-Fehlern hast Du im Grunde drei Möglichkeiten:
- Wenn der Inhalt der Seite nicht mehr existiert, solltest Du sicherstellen, dass Dein Server einen 404-Fehlercode zurücksendet.
- Wenn der Inhalt an eine andere Stelle verschoben wurde, solltest Du per 301-Redirect weiterleiten und etwaige interne Links an die neue URL anpassen.
- Wenn die Seite fälschlicherweise als Soft 404-Fehler kategorisiert wurde (z. B. aufgrund von Thin Content), kann der Fehler durch die Verbesserung der Inhalte behoben werden.
Weitere Details findest Du in unserem Wiki-Artikel über Soft 404-Fehler.
6. Mach es Google möglichst leicht, Deine besten Inhalte zu finden
Um Dein Crawl Budget weiter optimal zu nutzen, solltest Du Googlebot nicht nur von minderwertigen oder irrelevanten Inhalten fernhalten, sondern ihn auch gezielt zu Deinen hochwertigen Inhalten lenken. Das kannst Du mit folgenden Elementen:
- XML-Sitemaps
- Interne Links
- Flache Seitenarchitektur
Nutze eine XML-Sitemap
Eine XML-Sitemap bietet eine klare Übersicht über die Inhalte Deiner Website und ist eine hervorragende Strategie, um Google zu zeigen, welche Seiten gecrawlt und indexiert werden sollen. So machst Du das Crawling schneller und die Chance ist geringer, dass dabei hochwertige und wichtige Inhalte ausgelassen werden.
Nutze interne Verlinkungen strategisch
Suchmaschinen-Bots durchsuchen Websites, indem Sie internen Verlinkungen folgen. Du kannst diese Links also auch strategisch einsetzen, um Crawler auf bestimmte Seiten zu lenken. Dies ist besonders nützlich für Seiten, die häufiger gecrawlt werden sollen. Platziere interne Links zu diesen Seiten von anderen Unterseiten mit starken Backlinks oder hohem Traffic, um sie für Google leichter auffindbar zu machen.
Wir empfehlen außerdem, wichtige Unterseiten häufiger auf Deiner Website zu verlinken, um Google zu zeigen, dass sie hohe Relevanz haben. Diese Seiten sollten außerdem nur wenige Klicks von Deiner Startseite entfernt sein.
In unserem Leitfaden zur Optimierung der internen Verlinkung erfährst Du, wie Du diese Strategien konkret umsetzen kannst.
Verwende eine flache Seitenarchitektur
Bei einer flachen Seitenarchitektur sind alle Unterseiten Deiner Website nicht mehr als 4 bis 5 Klicks von der Startseite entfernt. Das hilft dem Googlebot, die Struktur Deiner Website zu verstehen und schützt Dein Crawl Budget vor allzu komplexem Crawling.
Mit Seobility kannst Du die Klickdistanz Deiner Seiten einfach analysieren:
Seobility > Onpage > Struktur > Seitenebenen Verteilung
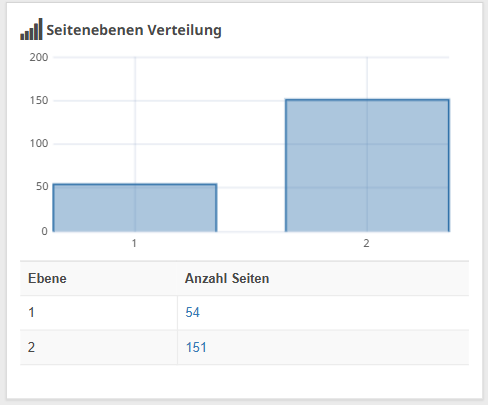
Wenn wichtige Seiten mehr als 5 Klicks von Deiner Startseite entfernt sind, solltest Du versuchen, sie auf einer höheren Ebene zu verlinken, damit sie nicht von Google übersehen werden.
Strategien zur Erhöhung Deines Crawl Budgets
Bisher haben wir uns darauf konzentriert, Dein bestehendes Crawl Budget möglichst effizient zu nutzen. Wie eingangs erwähnt, gibt es jedoch auch Möglichkeiten, das Crawl Budget, das Google für Deine Website bereitstellt, insgesamt zu erhöhen.
Kurze Erinnerung: Es gibt zwei grundlegende Faktoren, die Dein Crawl Budget bestimmen: Crawl Rate und Crawl Demand. Um das Crawl Budget Deiner Webseite zu erhöhen, solltest Du Dich auf diese beiden Hauptfaktoren konzentrieren.
Crawl Rate erhöhen
Die Crawl Rate hängt stark von der Leistungsfähigkeit Deines Servers und seiner Reaktionszeit ab. In der Regel gilt: Je besser die Serverleistung und je schneller die Reaktionszeit, desto wahrscheinlicher ist es, dass Google die Crawl Rate erhöht.
(Das funktioniert jedoch nur, wenn auch genügend Crawl Demand vorhanden ist, denn eine Verbesserung der Serverleistung bringt nichts, wenn Google Deinen Content nicht auch crawlen will.)
Wenn ein Upgrade Deines Servers nicht in Frage kommt, gibt es einige Onpage-SEO-Techniken, um die Serverlast zu reduzieren. Dazu gehören die Implementierung von Caching, die Optimierung und das Lazy-Loading Deiner Bilder sowie die Aktivierung von GZip-Komprimierung.
In diesem Leitfaden zur Page Speed Optimierung erfährst Du, wie Du diese Tipps umsetzen kannst. Außerdem zeigen wir Dir diverse weitere Techniken, um die Reaktionszeiten Deines Servers und den allgemeinen Page Speed zu verbessern.
Crawl Demand steigern
Du kannst zwar nicht aktiv steuern, wie viele Seiten Google crawlen will, doch Du kannst die Wahrscheinlichkeit erhöhen, dass Google Deiner Website mehr Zeit widmen möchte:
- Vermeide Thin Content oder Inhalte, die als Spam interpretiert werden könnten. Konzentriere Dich stattdessen darauf, hochwertigen, hilfreichen Content zu erstellen.
- Nutze die oben erklärten Strategien zur effizienten Nutzung Deines Crawl Budgets. Indem Du sicherstellst, dass Google nur relevante und hochwertige Inhalte crawlt, schaffst Du eine Umgebung, in der die Suchmaschine den Wert Deiner Website erkennt und sie häufiger crawlen will. Google lernt, dass Deine Website es wert ist, ausführlich erkundet zu werden, was eine Erhöhung des Crawl Demands zur Folge haben kann.
- Bau starke Backlinks auf, steigere das User-Engagement und teile Deine Seiten auf Social Media. Das steigert die Beliebtheit Deiner Website und weckt Interesse.
- Halte Deinen Content aktuell, da Google aktuelle und hochwertige Inhalte für seine User priorisiert.
So, jetzt haben wir Dir einige Strategien gezeigt, um mögliche Probleme mit dem Crawl Budget in den Griff zu bekommen. Zu guter Letzt haben wir noch ein paar Tipps für Dich, wie Du den Fortschritt Deiner Crawl-Budget-Optimierung im Auge behalten kannst.
So überwachst Du den Fortschritt Deiner Crawl-Budget-Optimierung
Wie viele SEO-Aufgaben ist auch die Optimierung des Crawl Budgets kein Prozess, der an einem Tag erledigt ist. Die Optimierung muss konstant beobachtet und nachgebessert werden, damit Google stets die wichtigen Seiten Deiner Website leicht findet.
Mit den folgenden Reports kannst Du im Blick behalten, wie Google Deine Website crawlt:
Crawl-Statistiken in der Google Search Console
In diesem Report siehst Du die Anzahl der pro Tag gecrawlten Seiten Deiner Website für die letzten 90 Tage.
Einstellungen > Crawling-Statistiken
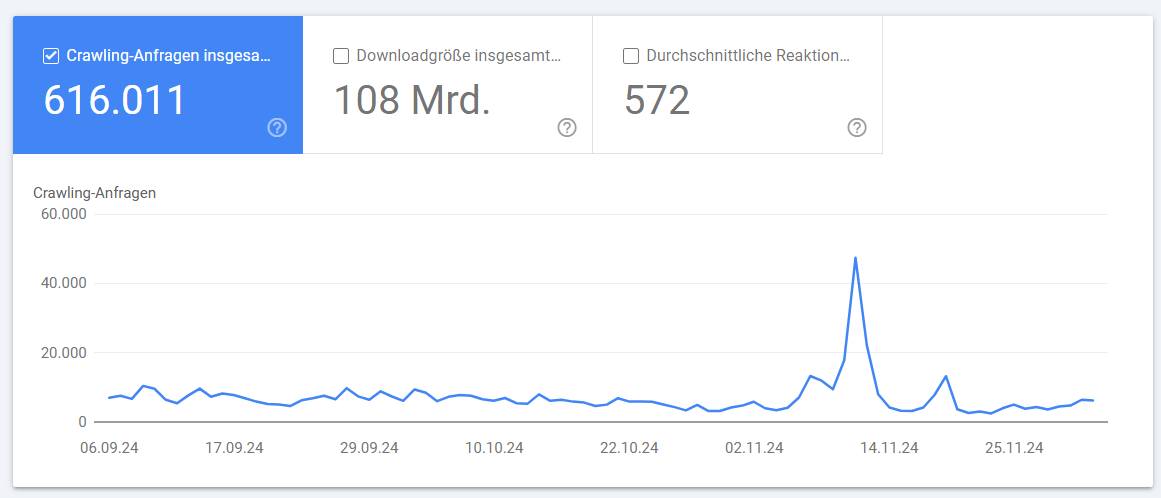
Ein plötzlicher Rückgang des Crawling-Volumens kann auf Probleme hindeuten, die Google daran hindern, Deine Website erfolgreich zu crawlen. Wenn Deine Optimierungsmaßnahmen erfolgreich sind, solltest Du jedoch einen Anstieg der Crawling-Anfragen beobachten können.
Bei einem sehr plötzlichen Anstieg des Crawling-Volumens solltest Du allerdings aufpassen: Das kann ein Hinweis auf neue Probleme sein, wie z. B. neue Infinite Spaces oder große Mengen an Spam-Content, die durch einen Hackerangriff auf Deine Website entstanden sind. In diesem Fall muss Google sehr viele neue URLs abrufen.
Um die genaue Ursache für einen plötzlichen Anstieg dieser Metrik zu finden, solltest Du daher Deine Server-Logfiles analysieren.
Logfile-Analyse
Webserver nutzen Logfiles, um jeden Besuch auf Deiner Website zu protokollieren. Sie speichern Informationen wie IP-Adresse, User-Agent usw. Durch die Analyse Deiner Logfiles kannst Du herausfinden, welche Seiten vom Googlebot häufiger gecrawlt werden und ob es die richtigen (d. h. relevanten) Seiten sind. Außerdem kannst Du prüfen, ob es Seiten gibt, die Dir sehr wichtig sind, die aber von Google beim Crawling ausgelassen werden.
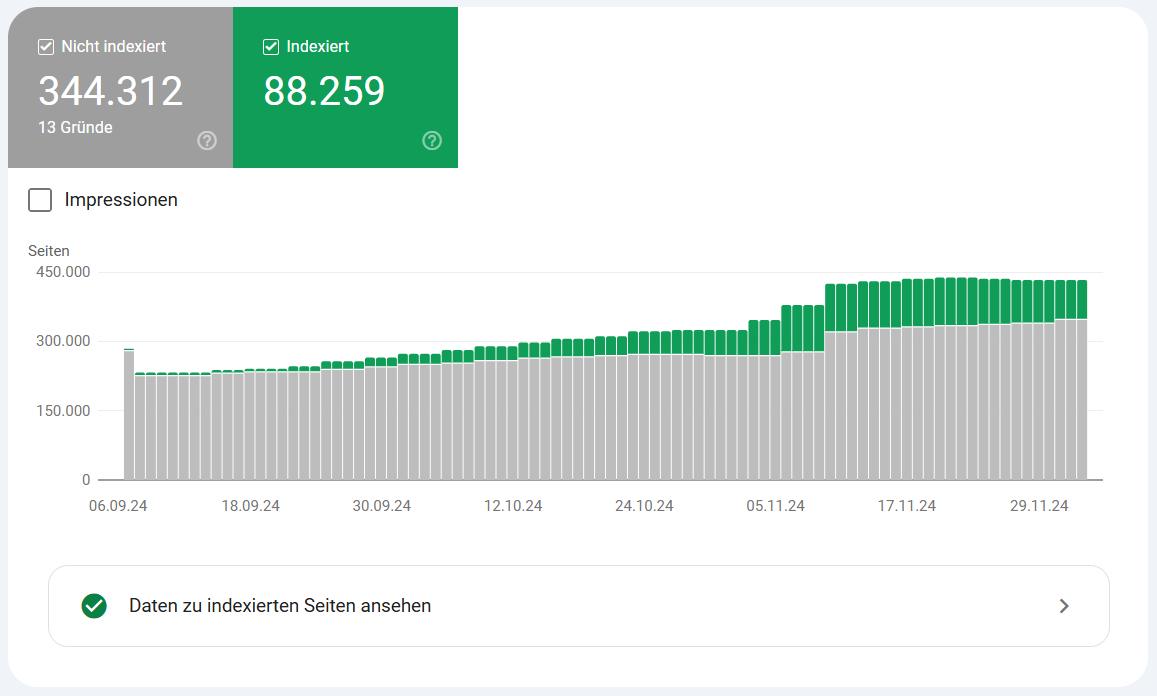
Report zur Indexabdeckung
Dieser Report in der Search Console zeigt Dir, wie viele Seiten Deiner Website tatsächlich von Google indexiert wurden. Außerdem siehst Du die genauen Gründe, warum andere Seiten nicht indexiert sind.
Google Search Console > Indexierung > Seiten
Optimiere Dein Crawl Budget für eine bessere SEO-Performance
Je nach Größe Deiner Website kann das Crawl Budget eine entscheidende Rolle für das Ranking Deiner Inhalte spielen. Doch ohne die richtige Optimierung könnten Suchmaschinen Schwierigkeiten haben, Deine Inhalte zu indexieren. Das kann Deine Bemühungen, hochwertigen Content zu erstellen, schnell zunichtemachen.
Und besonders bei JavaScript-basierten Websites ist die Bedeutung des Crawl Budgets noch größer. Dynamische JS-Inhalte benötigen nämlich mehr Crawl Budget für die Indexierung. Verlass Dich also nicht darauf, dass Google die Indexierung schon richtig macht, sondern sorge mit unseren Tipps dafür, dass Deine Website ihr volles SEO-Potenzial entfaltet!
Noch Fragen? Hinterlasse gerne einen Kommentar!
PS: Erhalte neue Blog Artikel direkt in Dein Postfach!
13 Gedanken zu „Crawl Budget Optimierung: So verbesserst Du das Crawling Deiner Website“
Hey,
vielen Dank für den tollen Artikel. Das „Crawl-Budget“ war mir gar nicht so bewußt. Jetzt achte ich da vermehrt drauf.
Ich freue mich auf mehr solcher Tipps.
Sehr gerne, Boris, danke für Dein Feedback!
Hallo,
Macht es Sinn.css/?223. in der Rotos.txt mittels Wildcard auszuschließen?
Gruß Freddy
Hallo Freddy,
bei sehr großen Websites kann es Sinn machen, CSS-Dateien mit dynamischen Parametern in der Robots.txt auszuschließen, um das Crawl Budget zu schonen. Allerdings solltest Du beachten, dass Google oft auch CSS-Dateien lädt, um die Darstellung einer Webseite auf mobilen Endgeräten zu prüfen. Daher ist hier Vorsicht geboten.
Schöner Artikel. Sehr hilfreich. 🙂
Hey Jan, danke für das positive Feedback! 🙂
Guten Morgen,
da ich blutiger Anfänger bin erschlagen mich die vielen Infos.
Werde mich so nach und nach einarbeiten und die vielen Beiträge lesen.
Danke für die ausgezeichneten Seiten
Guter Artikel und nett zum Lesen. Ich denke jeder der sich daran hält wird auf seiner Seite schnelle Verbesserungen bemerken. Man muss Google verstehen um Google richtig für einen arbeiten zu lassen 😉
Übrigens finde ich es gut, dass ihr immer viele Beispiele bringt.
Hallo Patrick,
danke für das Lob!
Wir versuchen unsere Texte immer mit vielen Beispielen so verständlich und praxisnah wie möglich zu schreiben. Freut uns, dass das auch von unseren Lesern wahrgenommen und geschätzt wird 🙂
Ich liebe euren Blog!
So viele wichtige Informationen und so verständlich geschrieben, ich kann immer wieder nur Danke für Eure tolle Arbeit sagen.
Grüße aus Berlin
Karsten
Hallo Karsten, vielen Dank für die netten Worte! 🙂
Hallo liebes SEOBILITY Team.
Danke für die Infos, guter Artikel. Bei dem Begriff Paginierung komme ich dann doch ins Straucheln. Was war das doch gleich nochmals???? Ach ja…… Guter Hinweis, aber in der Erklärung etwas verwirrend wegen Duplicate Content.
Hallo Robert,
vielen Dank für Dein Feedback! Eine Paginierung bzw. Pagination ist eine Seitennummerierung, d.h. Website Inhalte werden auf mehrere Seiten aufgeteilt. Mehr Informationen dazu findest Du auch in unserem Wiki Artikel: https://www.seobility.net/de/wiki/Pagination
Wir möchten, dass unsere Artikel für jeden verständlich sind, wenn Du also noch weitere Fragen hast, dann melde Dich gerne bei uns!