
Webseiten, die JavaScript nutzen, sind mittlerweile aus dem Web nicht mehr wegzudenken. Gerade wenn es um die Interaktion mit Besuchern und die dynamische Darstellung von Inhalten geht, führt kein Weg an der Skriptsprache vorbei. Leider haben Bots und Crawler in der Vergangenheit lediglich den HTML Code einer Webseite analysiert und damit war die Erfassung von dynamischen Inhalten, die mittels JavaScript erzeugt wurden, für Suchmaschinen nicht möglich. Da Suchmaschinen wie Google dem Nutzer allerdings das beste Ergebnis liefern möchten, liegt es nahe, dass Websites mit JavaScript ebenfalls korrekt erfasst werden sollten.
Google hat daher Ende 2015 verkündet, dass JavaScript und CSS genauso wie in modernen Web-Browsern von der Suchmaschine gerendert und analysiert wird. Der bisherige Standard für das AJAX Crawling mittels “_escaped_frament_” wurde somit auch als veraltet eingestuft und enthält damit von Google keine Empfehlung mehr. (https://webmasters.googleblog.com/2015/10/deprecating-our-ajax-crawling-scheme.html)
Javascript und SEO
Noch vor wenigen Jahren hätte man sich die Frage gar nicht gestellt, ob JavaScript für Suchmaschinen optimierte Seiten eingesetzt werden sollte. Die Antwort war ganz klar “Nein”, zumindest für die Darstellung von Content, da Crawler dynamisch generierte Inhalte nicht indizieren konnten. Mittlerweile hat sich das, zumindest bei Google, geändert und neue JavaScript Frontend Frameworks und “Rich-Client” Anwendungen machen es teilweise notwendig über eine Koexistenz von JavaScript und SEO nachzudenken.
Im Grunde müssen sich Website Betreiber die Frage stellen, welches Ziel sie verfolgen wollen. JavaScript ist perfekt für die Nutzerinteraktion in Webanwendungen, Communitys usw. geeignet, sollen Inhalte aber auch der Öffentlichkeit und damit der Suchmaschine verfügbar gemacht werden, muss auf eine entsprechende Indexierbarkeit geachtet werden. Content orientierte Webseiten wie Blogs, Verzeichnisse oder auch Online Shops sollten hingegen sicherstellen, dass der Hauptinhalt bereits in der vom Server bereitgestellten HTML Seite vorhanden ist, zumal Google bisher die einzige Suchmaschine ist, die JavaScript ausführt, um den generierten Seiteninhalt zu indexieren.
Folgendes ist beim Einsatz von JavaScript dringend zu beachten:
- Wichtige Inhalte wie Seitentitel, Überschriften und Textinhalt sollten weiterhin im, vom Server generierten, HTML Code eingebunden werden
- Nur Google führt bisher beim Crawlen JavaScript aus, andere Suchmaschinen (Bing, Yahoo, etc.) rendern die Seite (noch) nicht
- Jede Seite braucht eine eindeutige URL, möglichst ohne “#” Hashtag. (Die URL ist sozusagen die ID in der Index Datenbank der Suchmaschine, ohne geht es nicht)
- SPA (Single Page Applications) die komplett mit JavaScript Frontend Frameworks erstellt wurden, sollten Prerendering (z.B. prerender.io) nutzen, um Crawlern einen
bereits generierten HTML Code bereitzustellen - Dynamischer Inhalt, der erst durch Nutzerinteraktion eingebunden wird, kann nicht von Suchmaschinen indiziert werden (Der Bot klickt nicht!)
Abruf wie durch Google (Search Console)
Google stellt in seiner Search Console (ehemals. Webmaster Tools) eine Funktion bereit, mit der Webseiten vom Googlebot abgerufen und gerendert werden können. Dabei kommt als Web Rendering Service (WRS) der Chrome Browser in der Version 41 zum Einsatz. Über die Funktion “Abruf wie durch Google” kann geprüft werden, ob Google die Webseite korrekt erfasst und Inhalte richtig dargestellt werden
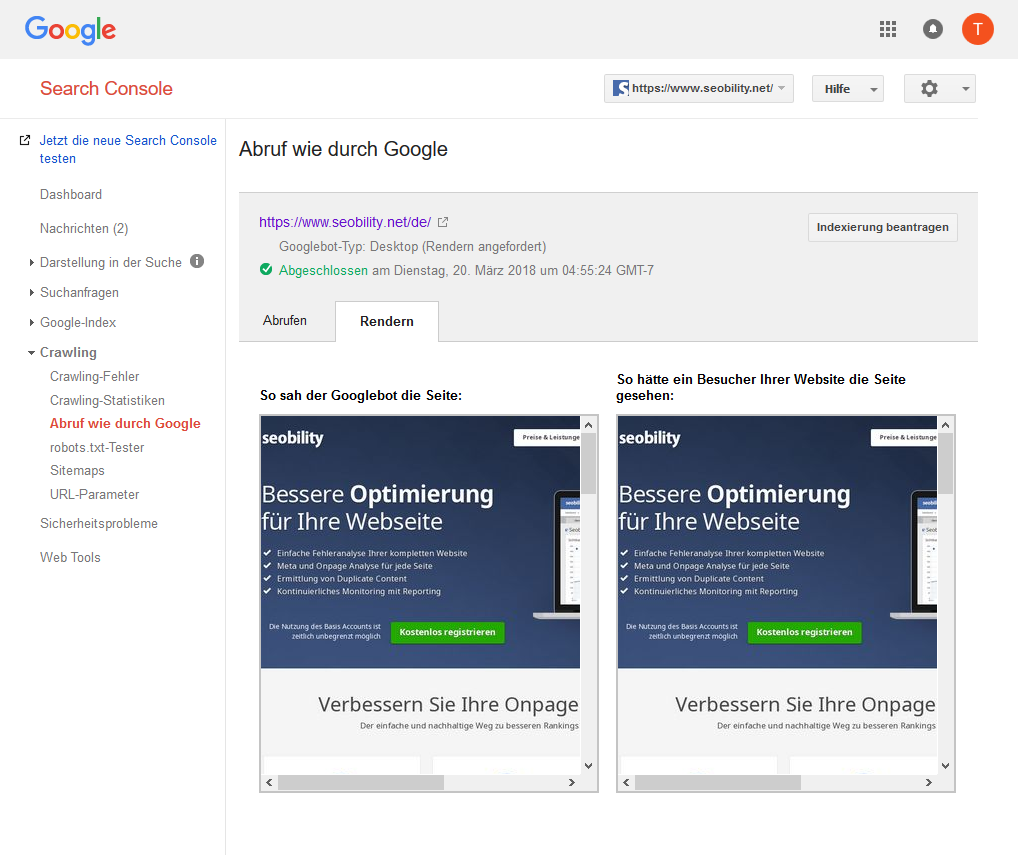
Aktivierung von JavaScript Crawling bei Seobility
Wir haben das JavaScript Crawling sowohl für das komplette Crawling einer Website, als auch für den SEO Check (Einzelanalyse) bereitgestellt.
Projekt mit JavaScript Crawling
In den Crawlereinstellungen des jeweiligen Projektes kannst Du den gewünschten Crawling Modus auswählen. Für JavaScript Crawling wählst Du “Chrome (mit JavaScript)”. Zusätzlich kannst Du eine Wartezeit in Millisekunden angeben, wie lange nach dem Laden der Seite gewartet werden soll, bis der generierte Quelltext gespeichert und ausgewertet wird. Bitte beachte, dass beim JavaScript Crawling die gesamte Crawlingdauer je nach Website stark zunimmt. Neben dem Download der Webseite werden natürlich auch, wie beim Surfen durch einen Besucher, sämtliche benötigte Ressourcen wie JS und CSS Dateien abgerufen, was die Anzahl der einzelnen Zugriffe auf den Webserver stark erhöht.
Hinweis: Das JavaScript Crawling stellt sicher, dass der generierte Quellcode mit sämtlichen Inhalten, die per JavaScript nachgeladen oder erstellt werden, von Seobility analysiert wird. Es wird hingegen nicht die Nutzung von JavaScript mit Rendering Pfad usw. geprüft, auch für die Seitenladezeit ist weiter die Wartezeit bis die HTML Seite vom Server heruntergeladen wurde maßgeblich.
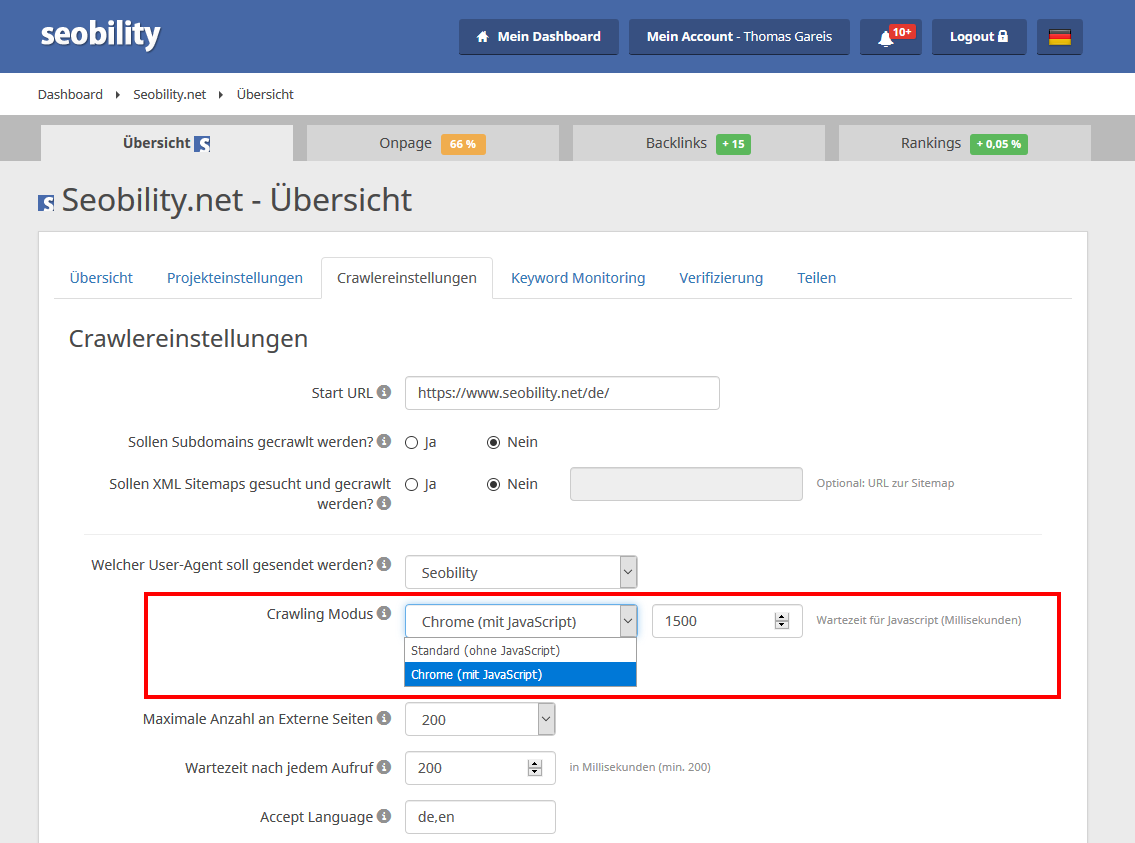
SEO Check mit JavaScript Crawling
Der SEO Check, mit dem Du schnell und einfach eine einzelne Seite nach SEO Kriterien prüfen kannst, erlaubt in den erweiterten Einstellungen das Crawling mit ausgeführtem JavaScript. Wähle bei Crawling Modus “Chrome”, um den generierten Quellcode der angegebenen Seite zu analysieren.
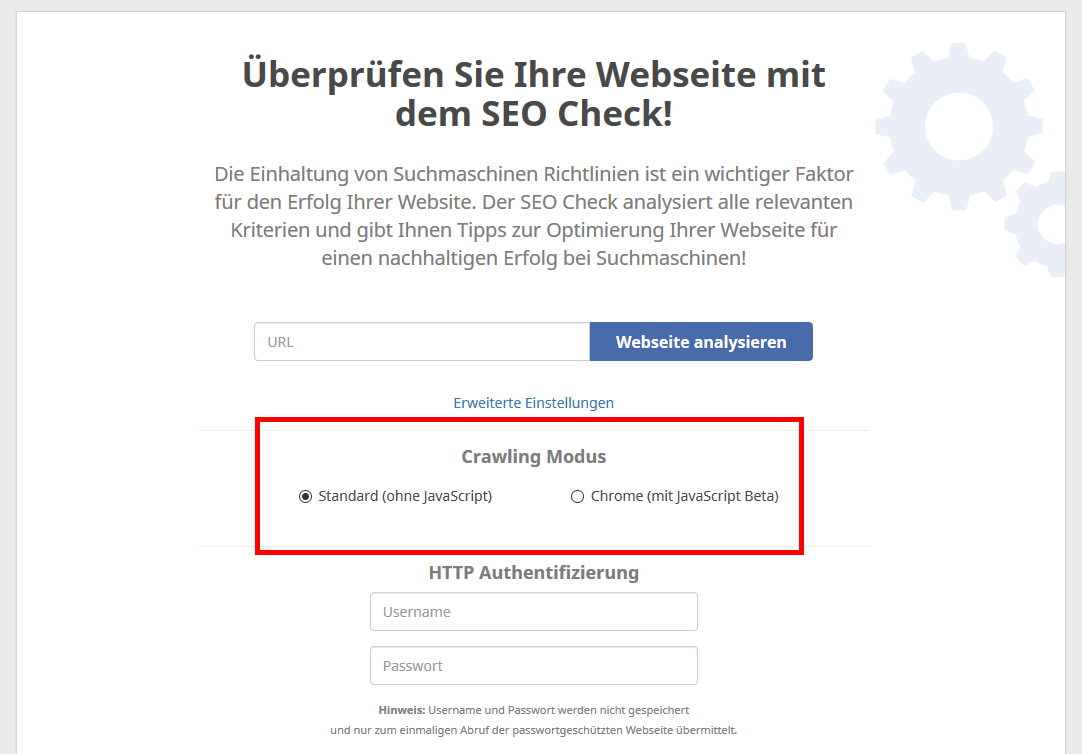
Wichtige Hinweise zum JavaScript Crawling
Bitte beachte folgende Hinweise, wenn Du Websites mit Chrome bzw. ausgeführtem JavaScript crawlst:
- Das Crawling des gesamten Projektes wird 3-5 mal so lange dauern als ohne JavaScript
- Sämtliche benötigte Ressourcen zum Erstellen der Seite wie z.B. JavaScript oder CSS Dateien müssen für den Crawler erreichbar sein bzw. dürfen nicht per robots.txt
ausgeschlossen werden - Jede einzelne Seite sollte eine eindeutige URL aufweisen
- Sämtlicher relevanter Inhalt sollte kurz nach dem Laden der Website (Load-Event) verfügbar sein und nicht erst durch zusätzliche Nutzerinteraktion geladen werden.
Fazit
Der Einsatz von JavaScript für dynamische Inhalte ist gerade hinsichtlich Suchmaschinenoptimierung mit Vorsicht zu genießen. Es gibt keine Garantie, dass Google und andere Suchmaschinen den Inhalt korrekt indexieren. Wenn JavaScript neben der Nutzerinteraktion auch für die Bereitstellung der eigentlichen Inhalte eingesetzt wird, sollte dringend geprüft und überwacht werden, ob Crawler sämtliche Seiten und Seiteninhalte auffinden können. Dies kann mit dem von Seobility bereitgestellten JavaScript Crawling erfolgen, wobei eine direkte Prüfung über die Google Search Console oder gar über eine direkte Google Suche (z.B. site:example.com “Text der erst durch JavaScript erzeugt wird”) letzte Gewissheit gibt, ob der Content auch wirklich im Suchindex landet. Ob Google den Inhalt, der sich bereits auf der vom Server erzeugten HTML Seite befindet und Inhalt, der nachträglich von JavaScript erzeugt wird gleich bewertet, bleibt offen.
Lesenswertes zum Thema JavaScript Crawling:
https://koschklinkperformance.de/javascript-seo/
https://support.google.com/webmasters/answer/81766?hl=de
Bild: programming banner, @fotolia/danijelala
PS: Erhalte neue Blog Artikel direkt in Dein Postfach!
3 Gedanken zu „JavaScript Crawling und SEO“
Guter Artikel – Vielen Dank!
Vielen Dank, dass ihr diese Möglichkeit bietet! Bei manchen Seiten braucht man JavaScript Crawling mittlerweile um einen korrekten Site Audit zu erstellen.
Persönlich würde ich JS für die Content Auslieferung nur in eingeloggten Nutzerbereichen verwenden… aber das sehen sogar manchen CMS Plugins etc. mittlerweile anders.
Sehr Gut