GET-Parameter: Unterschied zwischen den Versionen
(→Ähnliche Artikel) |
|||
| (19 dazwischenliegende Versionen von 2 Benutzern werden nicht angezeigt) | |||
| Zeile 1: | Zeile 1: | ||
| + | <seo title="GET Parameter: Definition und Funktionsweise" metadescription="GET-Parameter (auch: URL-Parameter) werden genutzt, wenn ein Client mittels HTTP-Protokoll eine bestimmte Ressource von einem Webserver anfordert." /> | ||
| + | |||
== Definition == | == Definition == | ||
| + | [[File:GET-Parameter.png|mini|450px|rechts|alt=GET-Parameter|'''Abbildung:''' GET-Parameter - Autor: Seobility - Lizenz: [[Creative Commons Lizenz BY-SA 4.0|CC BY-SA 4.0]]|link=https://www.seobility.net/de/wiki/images/5/52/GET-Parameter.png]] | ||
| + | GET-Parameter (auch: URL-Parameter) werden genutzt, wenn ein Client, zum Beispiel ein Browser, mittels HTTP-Protokoll eine bestimmte Ressource von einem Webserver anfordert. GET Parameter sind üblicherweise Name-Wert-Paare, die durch ein Gleichheitszeichen <code>=</code> getrennt werden. | ||
| − | + | == Wie sehen URL-Parameter aus? == | |
| − | + | Eine beispielhafte URL könnte so aussehen: | |
| − | + | <pre>https://www.example.com/index.html?name1=value1&name2=value2</pre> | |
| − | + | Der GET-Parameter beginnt immer mit einem Fragezeichen <code>?</code>. Darauf folgt der Name der Variable und der zugehörige Wert, getrennt durch ein <code>=</code>. Enthält eine URL mehr als einen Parameter, werden diese durch ein kaufmännisches und <code>&</code> getrennt. | |
| − | + | [[File:Get-parameter-beispiel.png|border|link=|750px|alt=GET Parameter|Get Parameter im Webshop von H&M]] | |
| − | + | Screenshot mit GET Parameter von [https://www2.hm.com/de_de/damen/produkte/schuhe.html?sort=new hm.de]. | |
| − | + | == Verwendung von Get-Parametern == | |
| − | < | + | GET-Parameter lassen sich prinzipiell in <strong>aktiv</strong> und <strong>passiv</strong> unterteilen. Aktive Parameter modifizieren dabei den Content einer Seite beispielsweise durch: |
| − | + | * '''Filtern der Inhalte:''' <code>?type=green</code> zeigt etwa auf einer E-Commerce-Seite nur grüne Produkte an. | |
| + | * '''Sortieren der Inhalte:''' <code>?sort=price_ascending</code> sortiert die angezeigten Produkte nach Preis, in diesem Falle aufsteigend. | ||
| − | + | Passive GET-Parameter hingegen verändern den Inhalt einer Seite nicht und werden primär zum Sammeln von Nutzerdaten genutzt. Anwendungsbeispiele sind unter anderem: | |
| − | + | * '''Tracking von [[Session-ID]]s:''' <code>?sessionid=12345</code> So lassen sich Besuche einzelner Nutzer abspeichern, wenn Cookies abgelehnt wurden. | |
| + | * '''Tracking von [[Traffic]]:''' <code>?utm_source=google</code> Mithilfe von URL-Parametern lässt sich nachverfolgen, über welche Links Besucher auf die eigene Website gelangt sind. Diese UTM-Parameter (Urchin Tracking Module) funktionieren mit Analytics-Tools und können dabei helfen, den Erfolg einer Kampagne zu bewerten. Neben <code>source</code> stehen dabei <code>utm_medium</code>, <code>utm_campaign</code>, <code>utm_term</code> und<code>utm_content</code> zur Verfügung. Mehr Informationen dazu finden sich in Google's [[https://ga-dev-tools.appspot.com/campaign-url-builder/ Campaign URL Builder]]. | ||
| − | + | == Mögliche Probleme im Zusammenhang mit GET-Parametern == | |
| − | + | Enhthält eine Website zu viele Unterseiten mit URL-Parametern, kann dies dem Ranking selbiger schaden. Die häufigsten Probleme im Bezug auf GET-Parameter sind dabei <strong> Duplicate Content, Verschwendung von Crawl Budget und unleserliche URLs</strong>. | |
| − | == | + | === Duplicate-Content === |
Die Generierung der GET-Parameter, beispielsweise auf Basis der Einstellungen von Website-Filtern, kann schwerwiegende [[Duplicate Content]] Probleme bei E-Commerce-Seiten verursachen. Denn wenn Shopbesucher Filter verwenden können, um den Inhalt einer Seite zu sortieren oder einzugrenzen, werden zusätzliche URLs generiert, obwohl sich die Inhalte der Seiten nicht zwangsläufig unterscheiden. Zur Veranschaulichung dieses Problems soll folgendes Beispiel dienen: | Die Generierung der GET-Parameter, beispielsweise auf Basis der Einstellungen von Website-Filtern, kann schwerwiegende [[Duplicate Content]] Probleme bei E-Commerce-Seiten verursachen. Denn wenn Shopbesucher Filter verwenden können, um den Inhalt einer Seite zu sortieren oder einzugrenzen, werden zusätzliche URLs generiert, obwohl sich die Inhalte der Seiten nicht zwangsläufig unterscheiden. Zur Veranschaulichung dieses Problems soll folgendes Beispiel dienen: | ||
| − | Wenn die URL einer E-Commerce-Website die vollständige Liste aller vorhandenen Produkte in aufsteigender alphabetischer Reihenfolge enthält und der Benutzer die Produkte in absteigender Reihenfolge sortiert, ist die URL für die neue Sortierung <code>/all-products.html?sort=Z-A</code>. In diesem Fall hat die neue URL den gleichen Inhalt wie die ursprüngliche Seite, nur in einer anderen Reihenfolge. Dies ist allerdings problematisch, da diese Inhalte von Google als Duplicate Content gewertet werden können. Die Folge ist, dass Google nicht bestimmen kann, welche Seite in den Suchergebnissen angezeigt werden soll und welche Rankingsignale welcher der URLs zugeordnet werden sollen, wodurch sich die Relevanz auf die beiden Unterseiten aufteilt. Eine Lösung dieses Problems besteht darin, die Beziehung der Seiten zueinander eindeutig durch [[Canonical | + | <div style="border-style:solid; border-width:1px;border-color:rgb(170, 170, 170);padding:10px;"> |
| + | Wenn die URL einer E-Commerce-Website die vollständige Liste aller vorhandenen Produkte in aufsteigender alphabetischer Reihenfolge enthält und der Benutzer die Produkte in absteigender Reihenfolge sortiert, ist die URL für die neue Sortierung <code>/all-products.html?sort=Z-A</code>. In diesem Fall hat die neue URL den gleichen Inhalt wie die ursprüngliche Seite, nur in einer anderen Reihenfolge. Dies ist allerdings problematisch, da diese Inhalte von Google als Duplicate Content gewertet werden können. Die Folge ist, dass Google nicht bestimmen kann, welche Seite in den Suchergebnissen angezeigt werden soll und welche Rankingsignale welcher der URLs zugeordnet werden sollen, wodurch sich die Relevanz auf die beiden Unterseiten aufteilt. | ||
| + | </div> | ||
| + | |||
| + | Eine Lösung dieses Problems besteht darin, die Beziehung der Seiten zueinander eindeutig durch [[Canonical Tag|Canonical-Tags]] zu definieren. | ||
Canonical-Tags werden verwendet, um Suchmaschinen anzuzeigen, dass bestimmte Seiten als Kopien einer bestimmten URL behandelt werden sollen und dass alle Rankings tatsächlich der kanonischen URL gutgeschrieben werden sollten. Ein Canonical Tag kann im <head>-Bereich des HTML-Dokuments oder alternativ in den [[HTTP Header|HTTP-Header]] der Webseite eingefügt werden. Wird der Canonical Tag im <head>-Bereich implementiert lautet die Syntax beispielsweise: | Canonical-Tags werden verwendet, um Suchmaschinen anzuzeigen, dass bestimmte Seiten als Kopien einer bestimmten URL behandelt werden sollen und dass alle Rankings tatsächlich der kanonischen URL gutgeschrieben werden sollten. Ein Canonical Tag kann im <head>-Bereich des HTML-Dokuments oder alternativ in den [[HTTP Header|HTTP-Header]] der Webseite eingefügt werden. Wird der Canonical Tag im <head>-Bereich implementiert lautet die Syntax beispielsweise: | ||
| Zeile 39: | Zeile 49: | ||
Wird dieser Link allen URLs, die durch unterschiedliche Kombinationen von Filtern entstehen können, hinzugefügt, wird die Link Power all dieser Unterseiten auf die kanonische URL gebündelt und Google weiß, welche Seite in den SERPs angezeigt werden soll. | Wird dieser Link allen URLs, die durch unterschiedliche Kombinationen von Filtern entstehen können, hinzugefügt, wird die Link Power all dieser Unterseiten auf die kanonische URL gebündelt und Google weiß, welche Seite in den SERPs angezeigt werden soll. | ||
| − | Der Canonical Tag ist somit eine einfache Lösung, um [[Suchmaschinen Crawler]] zu dem Inhalt zu führen, den sie indexieren sollen. | + | Der Canonical Tag ist somit eine einfache Lösung, um [[Suchmaschinen Crawler]] zu dem Inhalt zu führen, den sie indexieren sollen. |
| + | |||
| + | === Verschwendung von Crawl Budget === | ||
| − | + | Google crawlt pro Website nur eine bestimmte Anzahl an URLs. Diese Menge an URLs wird Crawl Budget genannt. Mehr Informationen dazu finden sich im [https://www.seobility.net/de/blog/crawl-budget-optimierung/ Seobility Blog]. | |
| − | Grundsätzlich kann | + | Hat eine Website durch die Verwendung von URL-Parametern viele crawlbare URLs, so kann es passieren, dass Googlebot das Crawl Budget für die falschen Seiten verbraucht. Eine Methode, diesem Problem vorzubeugen, ist die [[Robots.txt|robots.txt]]. Darin kann festgelegt werden, dass der Googlebot URLs mit bestimmten Parametern nicht crawlen soll. |
| + | |||
| + | === Unleserliche URLs === | ||
| + | |||
| + | Zuviele Parameter in URLs können dazu führen, dass die URL für Nutzer schlecht zu lesen und schwer zu merken ist. Im schlimmsten Fall kann das [[Usability]] und der [[CTR (Click-Through-Rate)|Click-Through-Rate]] schaden. | ||
| + | |||
| + | Grundsätzlich kann sowohl Duplicate Content als auch Problemen mit Crawl Budget zumindest teilweise vorgebeugt werden, indem überflüssige Parameter in einer URL vermieden werden. | ||
| + | |||
| + | == Weiterführende Links == | ||
| + | |||
| + | * https://support.google.com/google-ads/answer/6277564?hl=de | ||
| + | |||
| + | == Ähnliche Artikel == | ||
| + | |||
| + | * [[HTTP Header]] | ||
[[Kategorie:Web Entwicklung]] | [[Kategorie:Web Entwicklung]] | ||
| + | |||
| + | <html><script type="application/ld+json"> | ||
| + | { | ||
| + | "@context": "https://schema.org/", | ||
| + | "@type": "ImageObject", | ||
| + | "contentUrl": "https://www.seobility.net/de/wiki/images/5/52/GET-Parameter.png", | ||
| + | "license": "https://creativecommons.org/licenses/by-sa/4.0/deed.de", | ||
| + | "acquireLicensePage": "https://www.seobility.net/de/wiki/Creative_Commons_Lizenz_BY-SA_4.0" | ||
| + | } | ||
| + | </script></html> | ||
| + | |||
| + | {| class="wikitable" style="text-align:left" | ||
| + | |- | ||
| + | |'''Über den Autor''' | ||
| + | |- | ||
| + | | [[File:Seobility S.jpg|link=|100px|left|alt=Seobility S]] Das Seobility Wiki Team besteht aus SEO-, Online-Marketing- und Web-Experten mit praktischer Erfahrung in den Bereichen Suchmaschinenoptimierung, Online-Marketing und Webentwicklung. Alle unsere Artikel durchlaufen einen mehrstufigen Redaktionsprozess, um Dir die bestmögliche Qualität und wirklich hilfreiche Informationen bieten zu können. <html><a href="https://www.seobility.net/de/wiki/Seobility_Wiki_Team" target="_blank">Mehr Informationen über das Seobility Wiki Team</a></html>. | ||
| + | |} | ||
| + | |||
| + | <html><script type="application/ld+json"> | ||
| + | { | ||
| + | "@context": "https://schema.org", | ||
| + | "@type": "Article", | ||
| + | "author": { | ||
| + | "@type": "Organization", | ||
| + | "name": "Seobility", | ||
| + | "url": "https://www.seobility.net/" | ||
| + | } | ||
| + | } | ||
| + | </script></html> | ||
Aktuelle Version vom 23. Januar 2024, 14:50 Uhr
Inhaltsverzeichnis
Definition
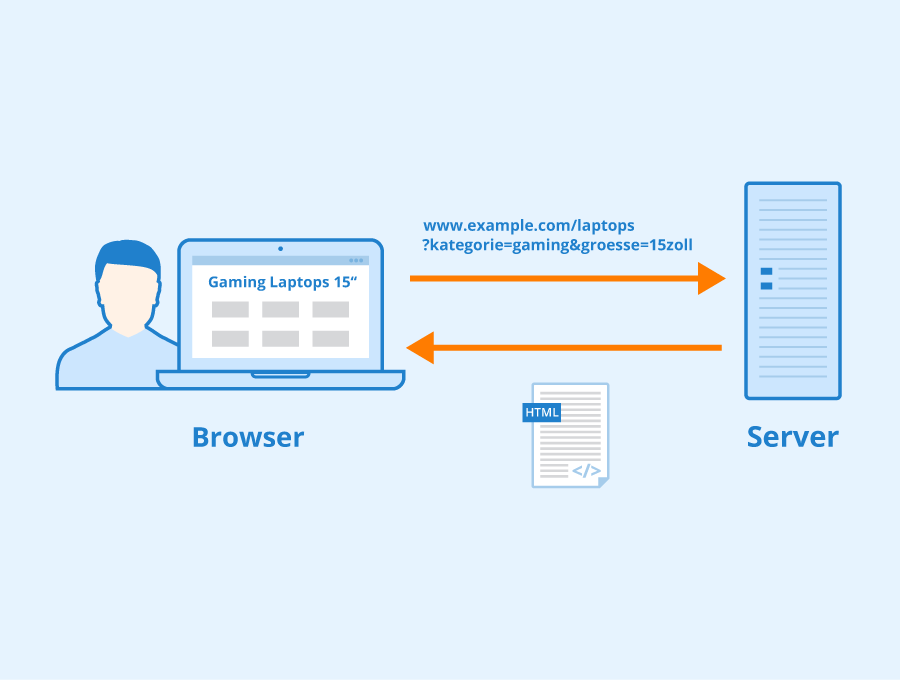
GET-Parameter (auch: URL-Parameter) werden genutzt, wenn ein Client, zum Beispiel ein Browser, mittels HTTP-Protokoll eine bestimmte Ressource von einem Webserver anfordert. GET Parameter sind üblicherweise Name-Wert-Paare, die durch ein Gleichheitszeichen = getrennt werden.
Wie sehen URL-Parameter aus?
Eine beispielhafte URL könnte so aussehen:
https://www.example.com/index.html?name1=value1&name2=value2
Der GET-Parameter beginnt immer mit einem Fragezeichen ?. Darauf folgt der Name der Variable und der zugehörige Wert, getrennt durch ein =. Enthält eine URL mehr als einen Parameter, werden diese durch ein kaufmännisches und & getrennt.

Screenshot mit GET Parameter von hm.de.
Verwendung von Get-Parametern
GET-Parameter lassen sich prinzipiell in aktiv und passiv unterteilen. Aktive Parameter modifizieren dabei den Content einer Seite beispielsweise durch:
- Filtern der Inhalte:
?type=greenzeigt etwa auf einer E-Commerce-Seite nur grüne Produkte an. - Sortieren der Inhalte:
?sort=price_ascendingsortiert die angezeigten Produkte nach Preis, in diesem Falle aufsteigend.
Passive GET-Parameter hingegen verändern den Inhalt einer Seite nicht und werden primär zum Sammeln von Nutzerdaten genutzt. Anwendungsbeispiele sind unter anderem:
- Tracking von Session-IDs:
?sessionid=12345So lassen sich Besuche einzelner Nutzer abspeichern, wenn Cookies abgelehnt wurden. - Tracking von Traffic:
?utm_source=googleMithilfe von URL-Parametern lässt sich nachverfolgen, über welche Links Besucher auf die eigene Website gelangt sind. Diese UTM-Parameter (Urchin Tracking Module) funktionieren mit Analytics-Tools und können dabei helfen, den Erfolg einer Kampagne zu bewerten. Nebensourcestehen dabeiutm_medium,utm_campaign,utm_termundutm_contentzur Verfügung. Mehr Informationen dazu finden sich in Google's [Campaign URL Builder].
Mögliche Probleme im Zusammenhang mit GET-Parametern
Enhthält eine Website zu viele Unterseiten mit URL-Parametern, kann dies dem Ranking selbiger schaden. Die häufigsten Probleme im Bezug auf GET-Parameter sind dabei Duplicate Content, Verschwendung von Crawl Budget und unleserliche URLs.
Duplicate-Content
Die Generierung der GET-Parameter, beispielsweise auf Basis der Einstellungen von Website-Filtern, kann schwerwiegende Duplicate Content Probleme bei E-Commerce-Seiten verursachen. Denn wenn Shopbesucher Filter verwenden können, um den Inhalt einer Seite zu sortieren oder einzugrenzen, werden zusätzliche URLs generiert, obwohl sich die Inhalte der Seiten nicht zwangsläufig unterscheiden. Zur Veranschaulichung dieses Problems soll folgendes Beispiel dienen:
Wenn die URL einer E-Commerce-Website die vollständige Liste aller vorhandenen Produkte in aufsteigender alphabetischer Reihenfolge enthält und der Benutzer die Produkte in absteigender Reihenfolge sortiert, ist die URL für die neue Sortierung /all-products.html?sort=Z-A. In diesem Fall hat die neue URL den gleichen Inhalt wie die ursprüngliche Seite, nur in einer anderen Reihenfolge. Dies ist allerdings problematisch, da diese Inhalte von Google als Duplicate Content gewertet werden können. Die Folge ist, dass Google nicht bestimmen kann, welche Seite in den Suchergebnissen angezeigt werden soll und welche Rankingsignale welcher der URLs zugeordnet werden sollen, wodurch sich die Relevanz auf die beiden Unterseiten aufteilt.
Eine Lösung dieses Problems besteht darin, die Beziehung der Seiten zueinander eindeutig durch Canonical-Tags zu definieren.
Canonical-Tags werden verwendet, um Suchmaschinen anzuzeigen, dass bestimmte Seiten als Kopien einer bestimmten URL behandelt werden sollen und dass alle Rankings tatsächlich der kanonischen URL gutgeschrieben werden sollten. Ein Canonical Tag kann im <head>-Bereich des HTML-Dokuments oder alternativ in den HTTP-Header der Webseite eingefügt werden. Wird der Canonical Tag im <head>-Bereich implementiert lautet die Syntax beispielsweise:
<link rel="canonical" href="https://www.example.com/all-products.html"/>
Wird dieser Link allen URLs, die durch unterschiedliche Kombinationen von Filtern entstehen können, hinzugefügt, wird die Link Power all dieser Unterseiten auf die kanonische URL gebündelt und Google weiß, welche Seite in den SERPs angezeigt werden soll.
Der Canonical Tag ist somit eine einfache Lösung, um Suchmaschinen Crawler zu dem Inhalt zu führen, den sie indexieren sollen.
Verschwendung von Crawl Budget
Google crawlt pro Website nur eine bestimmte Anzahl an URLs. Diese Menge an URLs wird Crawl Budget genannt. Mehr Informationen dazu finden sich im Seobility Blog.
Hat eine Website durch die Verwendung von URL-Parametern viele crawlbare URLs, so kann es passieren, dass Googlebot das Crawl Budget für die falschen Seiten verbraucht. Eine Methode, diesem Problem vorzubeugen, ist die robots.txt. Darin kann festgelegt werden, dass der Googlebot URLs mit bestimmten Parametern nicht crawlen soll.
Unleserliche URLs
Zuviele Parameter in URLs können dazu führen, dass die URL für Nutzer schlecht zu lesen und schwer zu merken ist. Im schlimmsten Fall kann das Usability und der Click-Through-Rate schaden.
Grundsätzlich kann sowohl Duplicate Content als auch Problemen mit Crawl Budget zumindest teilweise vorgebeugt werden, indem überflüssige Parameter in einer URL vermieden werden.
Weiterführende Links
Ähnliche Artikel
| Über den Autor |
 |