Suchmaschinen Crawler: Unterschied zwischen den Versionen
(Die Seite wurde neu angelegt: „= Definition = Ein Crawler ist eine Software, die das Internet durchsucht und dessen Inhalte analysiert. Sie wird vor allem von Suchmaschinen für die Indizie…“) |
(→Ähnliche Artikel) |
||
| (36 dazwischenliegende Versionen von 2 Benutzern werden nicht angezeigt) | |||
| Zeile 1: | Zeile 1: | ||
| − | = | + | <seo title="Suchmaschinen Crawler" metadescription="Was sind Suchmaschinen Crawler, wie arbeiten sie und wie kann die Crawlbarkeit der eigenen Website optimiert werden?" /> |
| − | + | == Definition == | |
| + | [[File:Suchmaschinen-Crawler.png|mini|450px|rechts|alt=Suchmaschinen Crawler|'''Abb.:''' Suchmaschinen Crawler - Autor: Seobility - Lizenz: [[Creative Commons Lizenz BY-SA 4.0|CC BY-SA 4.0]]|link=https://www.seobility.net/de/wiki/images/2/26/Suchmaschinen-Crawler.png]] | ||
| − | + | Ein Crawler ist eine Software, die das Internet durchsucht und dessen Inhalte analysiert. Sie wird vor allem von [[Suchmaschine]]n für die Indizierung von Webseiten verwendet. Darüber hinaus werden Webcrawler aber auch für die Datensammlung genutzt, z.B. für Web-Feeds oder, besonders im Marketing, E-Mail-Adressen. Crawler zählen zu den Bots, also Programmen, die automatisch definierte, sich wiederholende Aufgaben erledigen. Der erste Webcrawler hieß World Wide Web Wanderer und wurde ab 1993 zur Messung des Internetwachstums genutzt. Ein Jahr später startete die erste Internetsuchmaschine unter dem Namen Webcrawler und gab somit dieser Art von Programmen ihren Namen. Heute sind solche Bots der Hauptgrund, warum Suchmaschinenoptimierung (SEO) beim internetbasierten Marketing im Vordergrund steht. Für erfolgreiches SEO ist somit die Kenntnis über die Arbeitsweise dieser Programme von Vorteil, weshalb im Folgenden näher auf dieses Thema eingegangen wird. | |
| − | + | == Arbeitsweise von Webcrawlern == | |
| − | + | Ein Crawler findet neue Webseiten wie ein User beim Internetsurfen durch Hyperlinks. Wird eine Seite geöffnet, untersucht er sie und speichert alle enthaltenen [[URL|URLs]]. Danach öffnet er nach und nach jede der gespeicherten URLs, um den Vorgang zu wiederholen: Er analysiert und speichert weitere URLs. Auf diese Art nutzen Suchmaschinen Bots, um verlinkte Seiten im Web zu finden. Meist werden jedoch nicht alle URLs durch den Crawler abgearbeitet, sondern durch eine Auswahl begrenzt. Irgendwann wird der Vorgang gestoppt und neu eingeleitet. Die gesammelten Informationen werden in der Regel via Indizierung ausgewertet und gespeichert, damit sie sich schnell finden lassen. | |
| − | + | == Anweisungen an Webcrawler == | |
| − | + | Websitebetreiber können die Robots Exclusion Standards nutzen, um Crawlern mitzuteilen, welche Seiten indiziert werden sollen und welche nicht. Diese Anweisungen werden in einer Datei namens [[Robots.txt|robots.txt]] platziert oder können auch via [[Meta Tags|Meta-Tags]] im HTML-Header mitgeteilt werden. Dabei ist jedoch zu beachten, dass sich Crawler nicht immer an diese Anweisungen halten. | |
| − | Crawler finden ein breites Anwendungsspektrum und werden oft als Funktion eines Softwarepakets angeboten. Neben der für Suchmaschinen relevanten Indizierung des Webs, können die Programme genutzt werden, um thematisch fokussierte Informationen zu Sammeln. Wird die Suche des Crawlers durch Klassifizierung einer Website oder eines Links eingegrenzt, lassen sich ausschließlich thematisch relevante Seiten im Web finden. Darüber hinaus können Crawler für Data-Mining und Webometrie verwendet werden. Beim Data-Mining werden durch Bots Informationen aus großen Datenbeständen gesammelt, um Trends und Querverbindungen zu identifizieren. Durch die Verwendung von Bots lassen sich so relevante Datenbanken erstellen und zielgemäß auswerten. Die Webometrie befasst sich hingegen mit der Untersuchung des Internets auf Inhalte, Eigenschaften, Strukturen und das Userverhalten. | + | == Anwendungsszenarien von Crawler-Lösungen == |
| + | |||
| + | Crawler finden ein breites Anwendungsspektrum und werden oft als Funktion eines Softwarepakets angeboten. Neben der für Suchmaschinen relevanten Indizierung des Webs, können die Programme genutzt werden, um thematisch fokussierte Informationen zu Sammeln. Wird die Suche des Crawlers durch Klassifizierung einer Website oder eines Links eingegrenzt, lassen sich ausschließlich thematisch relevante Seiten im Web finden. Darüber hinaus können Crawler für [[Data Mining|Data-Mining]] und Webometrie verwendet werden. Beim Data-Mining werden durch Bots Informationen aus großen Datenbeständen gesammelt, um Trends und Querverbindungen zu identifizieren. Durch die Verwendung von Bots lassen sich so relevante Datenbanken erstellen und zielgemäß auswerten. Die Webometrie befasst sich hingegen mit der Untersuchung des Internets auf Inhalte, Eigenschaften, Strukturen und das Userverhalten. | ||
Eine besondere Art von Webcrawlern sind sogenannte Harvester („Erntemaschinen“). Diese Bezeichnung bezieht sich auf Programme, die das Web nach E-Mail-Adressen absuchen und diese „ernten“, also auf eine Liste für Aktivitäten wie Marketing oder Spamversand speichern. | Eine besondere Art von Webcrawlern sind sogenannte Harvester („Erntemaschinen“). Diese Bezeichnung bezieht sich auf Programme, die das Web nach E-Mail-Adressen absuchen und diese „ernten“, also auf eine Liste für Aktivitäten wie Marketing oder Spamversand speichern. | ||
| − | = Optimierung der Crawlbarkeit einer Webseite = | + | == Optimierung der Crawlbarkeit einer Webseite == |
| + | |||
| + | <html> | ||
| + | <div class="checkform"> | ||
| + | <div class="hl"> | ||
| + | <h3>Crawlbarkeit SEO Check</h3> | ||
| + | <p>Prüfe die Crawlbarkeit Deiner Seite</p> | ||
| + | </div> | ||
| + | <form action="https://www.seobility.net/de/seocheck/check#crawlability" method="get" target="_blank"> | ||
| + | <input type="text" name="url" required="required" placeholder="https://www.example.com/"><input type="submit" value="Crawlbarkeit prüfen"> | ||
| + | </form> | ||
| + | </div> | ||
| + | </html> | ||
| − | Um eine maximale Crawlbarkeit und ein bestmögliches SEO-Ergebnis zu erreichen, sollte eine Website eine gute interne Verlinkung aufweisen. Bots folgen Links, um neue Webseiten und Inhalte zu analysieren. Eine suchmaschinenfreundliche Verlinkung sorgt dafür, dass alle wichtigen Unterseiten von Suchbots gefunden werden können. Wird auf einer dieser Webseiten hochwertiger Inhalt entdeckt, ist wiederum ein hohes Ranking wahrscheinlich. | + | Um eine maximale Crawlbarkeit und ein bestmögliches SEO-Ergebnis zu erreichen, sollte eine Website eine gute [[interne Verlinkung]] aufweisen. Bots folgen Links, um neue Webseiten und Inhalte zu analysieren. Eine suchmaschinenfreundliche Verlinkung sorgt dafür, dass alle wichtigen Unterseiten von Suchbots gefunden werden können. Wird auf einer dieser Webseiten [[Content is King|hochwertiger Inhalt]] entdeckt, ist wiederum ein hohes Ranking wahrscheinlich. |
Um den Crawlern die Arbeit zu erleichtern, sind auch XML- oder HTML-Sitemaps eine gängige Lösung. Sie enthalten die komplette Linkstruktur einer Website, sodass eine Suchmaschine alle Unterseiten problemlos finden und indizieren kann. | Um den Crawlern die Arbeit zu erleichtern, sind auch XML- oder HTML-Sitemaps eine gängige Lösung. Sie enthalten die komplette Linkstruktur einer Website, sodass eine Suchmaschine alle Unterseiten problemlos finden und indizieren kann. | ||
| + | Nicht zu unterschätzen ist auch die korrekte Verwendung von HTML-Tags. Durch eine konsequente Verwendung dieser Strukturen kann man Bots helfen, den Inhalt einer Seite richtig zu interpretieren. Hierzu zählt zum Beispiel eine standardgemäße Nutzung von [[H1-H6 Überschrift|Überschriften]] (h1, h2, h3 usw.), Link-Titeln (title) und Bild-Beschreibungen (alt). | ||
| − | + | Weiterhin ist der Verzicht auf Java- oder Flash-Inhalte ratsam. Zwar ist Google inzwischen in der Lage, [[JavaScript]] Seiten zu crawlen, allerdings nimmt dies viel Crawling-Budget in Anspruch. Stattdessen sollten serverseitige Sprachen wie PHP oder ASP verwendet werden, um Navigationselemente und andere Bestandteile der Website in HTML zu erzeugen. Der Client (Webbrowser oder Bot) benötigt kein [[Plug-in]], um HTML-Ergebnisse zu verstehen und zu indizieren. | |
| − | |||
| − | Weiterhin ist der Verzicht auf Java- oder Flash-Inhalte ratsam. | ||
| − | Eine zeitgemäße Website sollte außerdem nicht mehr auf Frames basieren, sondern sämtliche designtechnischen Aspekte mit CSS lösen. Seiten, die heute noch Frames nutzen, werden nur teilweise indiziert und von Suchmaschinen missinterpretiert. | + | Eine zeitgemäße Website sollte außerdem nicht mehr auf [[Frames und Framesets|Frames]] basieren, sondern sämtliche designtechnischen Aspekte mit CSS lösen. Seiten, die heute noch Frames nutzen, werden nur teilweise indiziert und von Suchmaschinen missinterpretiert. |
| − | Ein weiterer wichtiger Aspekt hinsichtlich der Optimierung der Crawlbarkeit ist, dass Seiten, die für die Indizierung freigegeben werden sollen, nicht in der robots.txt ausgeschlossen sein und keinen „noindex“ Meta-Tag enthalten dürfen. Um zu prüfen, ob dieser Fall vorliegt, kann man auf verschiedene Tools der Suchanbieter zurückgreifen. Google beispielsweise stellt hierfür die Search Console für Webmaster zu Verfügung. | + | Ein weiterer wichtiger Aspekt hinsichtlich der Optimierung der Crawlbarkeit ist, dass Seiten, die für die Indizierung freigegeben werden sollen, nicht in der robots.txt ausgeschlossen sein und keinen „noindex“ Meta-Tag enthalten dürfen. Um zu prüfen, ob dieser Fall vorliegt, kann man auf verschiedene Tools der Suchanbieter zurückgreifen. Google beispielsweise stellt hierfür die [[Google Search Console|Search Console]] für Webmaster zu Verfügung. |
| − | Da Cyberkriminelle immer öfter Botangriffe veranlassen, nutzen Websitebetreiber den sogenannten Botschutz. Dieses Sicherheitssystem überwacht Zugriffe auf die Website, erkennt Bots und sperrt sie bei Bedarf aus. Ein falsch konfigurierter Botschutz kann aber auch Bots von Google, Bing und anderen Suchmaschinen blockieren, was dazu führt, dass Seiten nicht mehr indiziert werden. Daher sollte sichergestellt werden, dass der Botschutz vor der Sperrung die jeweilige IP-Adresse auf den Host prüft. Auf diese Weise wird erkannt, ob der Bot zu Google, Bing oder anderen Suchmaschinen gehört. | + | Da Cyberkriminelle immer öfter Botangriffe veranlassen, nutzen Websitebetreiber den sogenannten Botschutz. Dieses Sicherheitssystem überwacht Zugriffe auf die Website, erkennt Bots und sperrt sie bei Bedarf aus. Ein falsch konfigurierter Botschutz kann aber auch Bots von Google, Bing und anderen Suchmaschinen blockieren, was dazu führt, dass Seiten nicht mehr indiziert werden. Daher sollte sichergestellt werden, dass der Botschutz vor der Sperrung die jeweilige [[IP-Adresse]] auf den Host prüft. Auf diese Weise wird erkannt, ob der Bot zu Google, Bing oder anderen Suchmaschinen gehört. |
Abschließend ist darauf hinzuweisen, dass die Crawlbarkeit auch durch die Performance einer Website beeinflusst wird. Liegt die Internetpräsenz auf einem langsamen Server oder wird sie von technischen Problemen ausgebremst, erhält sie in der Regel kein gutes Suchmaschinenranking. Wahrscheinlich wird ein Teil der Unterseiten gar nicht indiziert, da Bots abspringen, wenn eine Seite zu lange lädt. Daher ist eine schnelle Infrastruktur die Grundlage für wirkungsvolle SEO. | Abschließend ist darauf hinzuweisen, dass die Crawlbarkeit auch durch die Performance einer Website beeinflusst wird. Liegt die Internetpräsenz auf einem langsamen Server oder wird sie von technischen Problemen ausgebremst, erhält sie in der Regel kein gutes Suchmaschinenranking. Wahrscheinlich wird ein Teil der Unterseiten gar nicht indiziert, da Bots abspringen, wenn eine Seite zu lange lädt. Daher ist eine schnelle Infrastruktur die Grundlage für wirkungsvolle SEO. | ||
| Zeile 38: | Zeile 52: | ||
Im Folgenden haben wir die soeben erläuterten Punkte nochmals in Form einer kurzen Checkliste für Sie zusammengefasst: | Im Folgenden haben wir die soeben erläuterten Punkte nochmals in Form einer kurzen Checkliste für Sie zusammengefasst: | ||
| + | * gute interne Verlinkung | ||
| + | * XML- oder HTML-Sitemap | ||
| + | * korrekte Verwendung von HTML-Tags | ||
| + | * Verzicht auf Java- oder Flash-Inhalte | ||
| + | * Verzicht auf Frames | ||
| + | * Überprüfung der durch robots.txt und "noindex" ausgeschlossenen Seiten | ||
| + | * richtige Konfiguration des Botschutzes | ||
| + | * schnelle Performance | ||
| + | |||
| + | == Weiterführende Links == | ||
| + | |||
| + | * https://www.seo-trainee.de/crawl-optimization-so-steuert-man-den-google-bot/ | ||
| + | |||
| + | == Ähnliche Artikel == | ||
| + | |||
| + | * [[Robots.txt]] | ||
| + | * [[XML-Sitemap]] | ||
| − | [[ | + | [[Kategorie:Suchmaschinenoptimierung]] |
| − | + | <html><script type="application/ld+json"> | |
| + | { | ||
| + | "@context": "https://schema.org/", | ||
| + | "@type": "ImageObject", | ||
| + | "contentUrl": "https://www.seobility.net/de/wiki/images/2/26/Suchmaschinen-Crawler.png", | ||
| + | "license": "https://creativecommons.org/licenses/by-sa/4.0/deed.de", | ||
| + | "acquireLicensePage": "https://www.seobility.net/de/wiki/Creative_Commons_Lizenz_BY-SA_4.0" | ||
| + | } | ||
| + | </script></html> | ||
| − | = | + | {| class="wikitable" style="text-align:left" |
| + | |- | ||
| + | |'''Über den Autor''' | ||
| + | |- | ||
| + | | [[File:Seobility S.jpg|link=|100px|left|alt=Seobility S]] Das Seobility Wiki Team besteht aus SEO-, Online-Marketing- und Web-Experten mit praktischer Erfahrung in den Bereichen Suchmaschinenoptimierung, Online-Marketing und Webentwicklung. Alle unsere Artikel durchlaufen einen mehrstufigen Redaktionsprozess, um Dir die bestmögliche Qualität und wirklich hilfreiche Informationen bieten zu können. <html><a href="https://www.seobility.net/de/wiki/Seobility_Wiki_Team" target="_blank">Mehr Informationen über das Seobility Wiki Team</a></html>. | ||
| + | |} | ||
| − | + | <html><script type="application/ld+json"> | |
| − | + | { | |
| + | "@context": "https://schema.org", | ||
| + | "@type": "Article", | ||
| + | "author": { | ||
| + | "@type": "Organization", | ||
| + | "name": "Seobility", | ||
| + | "url": "https://www.seobility.net/" | ||
| + | } | ||
| + | } | ||
| + | </script></html> | ||
Aktuelle Version vom 23. Januar 2024, 17:12 Uhr
Inhaltsverzeichnis
Definition
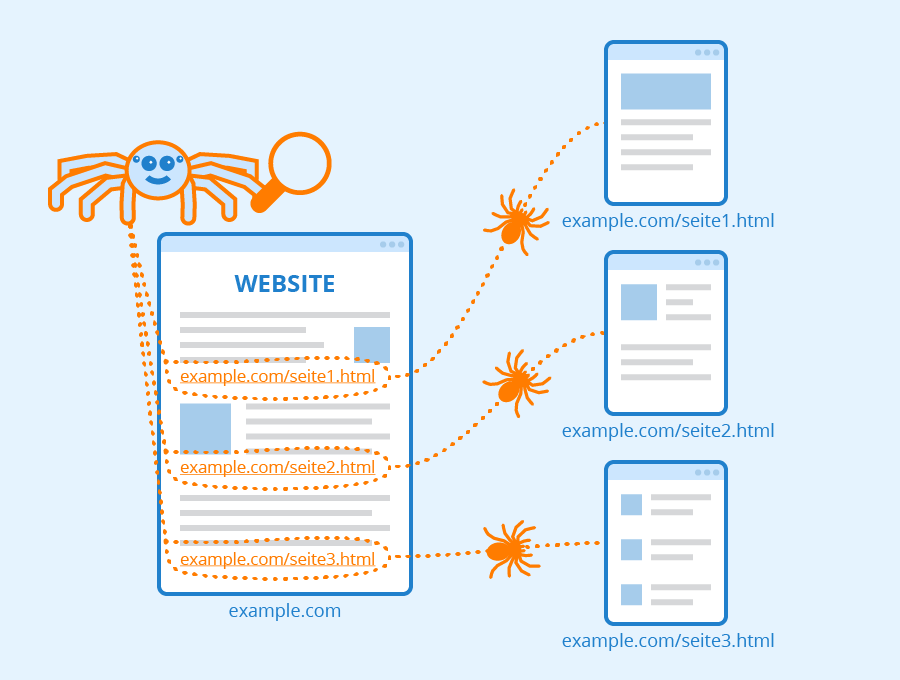
Ein Crawler ist eine Software, die das Internet durchsucht und dessen Inhalte analysiert. Sie wird vor allem von Suchmaschinen für die Indizierung von Webseiten verwendet. Darüber hinaus werden Webcrawler aber auch für die Datensammlung genutzt, z.B. für Web-Feeds oder, besonders im Marketing, E-Mail-Adressen. Crawler zählen zu den Bots, also Programmen, die automatisch definierte, sich wiederholende Aufgaben erledigen. Der erste Webcrawler hieß World Wide Web Wanderer und wurde ab 1993 zur Messung des Internetwachstums genutzt. Ein Jahr später startete die erste Internetsuchmaschine unter dem Namen Webcrawler und gab somit dieser Art von Programmen ihren Namen. Heute sind solche Bots der Hauptgrund, warum Suchmaschinenoptimierung (SEO) beim internetbasierten Marketing im Vordergrund steht. Für erfolgreiches SEO ist somit die Kenntnis über die Arbeitsweise dieser Programme von Vorteil, weshalb im Folgenden näher auf dieses Thema eingegangen wird.
Arbeitsweise von Webcrawlern
Ein Crawler findet neue Webseiten wie ein User beim Internetsurfen durch Hyperlinks. Wird eine Seite geöffnet, untersucht er sie und speichert alle enthaltenen URLs. Danach öffnet er nach und nach jede der gespeicherten URLs, um den Vorgang zu wiederholen: Er analysiert und speichert weitere URLs. Auf diese Art nutzen Suchmaschinen Bots, um verlinkte Seiten im Web zu finden. Meist werden jedoch nicht alle URLs durch den Crawler abgearbeitet, sondern durch eine Auswahl begrenzt. Irgendwann wird der Vorgang gestoppt und neu eingeleitet. Die gesammelten Informationen werden in der Regel via Indizierung ausgewertet und gespeichert, damit sie sich schnell finden lassen.
Anweisungen an Webcrawler
Websitebetreiber können die Robots Exclusion Standards nutzen, um Crawlern mitzuteilen, welche Seiten indiziert werden sollen und welche nicht. Diese Anweisungen werden in einer Datei namens robots.txt platziert oder können auch via Meta-Tags im HTML-Header mitgeteilt werden. Dabei ist jedoch zu beachten, dass sich Crawler nicht immer an diese Anweisungen halten.
Anwendungsszenarien von Crawler-Lösungen
Crawler finden ein breites Anwendungsspektrum und werden oft als Funktion eines Softwarepakets angeboten. Neben der für Suchmaschinen relevanten Indizierung des Webs, können die Programme genutzt werden, um thematisch fokussierte Informationen zu Sammeln. Wird die Suche des Crawlers durch Klassifizierung einer Website oder eines Links eingegrenzt, lassen sich ausschließlich thematisch relevante Seiten im Web finden. Darüber hinaus können Crawler für Data-Mining und Webometrie verwendet werden. Beim Data-Mining werden durch Bots Informationen aus großen Datenbeständen gesammelt, um Trends und Querverbindungen zu identifizieren. Durch die Verwendung von Bots lassen sich so relevante Datenbanken erstellen und zielgemäß auswerten. Die Webometrie befasst sich hingegen mit der Untersuchung des Internets auf Inhalte, Eigenschaften, Strukturen und das Userverhalten.
Eine besondere Art von Webcrawlern sind sogenannte Harvester („Erntemaschinen“). Diese Bezeichnung bezieht sich auf Programme, die das Web nach E-Mail-Adressen absuchen und diese „ernten“, also auf eine Liste für Aktivitäten wie Marketing oder Spamversand speichern.
Optimierung der Crawlbarkeit einer Webseite
Crawlbarkeit SEO Check
Prüfe die Crawlbarkeit Deiner Seite
Um eine maximale Crawlbarkeit und ein bestmögliches SEO-Ergebnis zu erreichen, sollte eine Website eine gute interne Verlinkung aufweisen. Bots folgen Links, um neue Webseiten und Inhalte zu analysieren. Eine suchmaschinenfreundliche Verlinkung sorgt dafür, dass alle wichtigen Unterseiten von Suchbots gefunden werden können. Wird auf einer dieser Webseiten hochwertiger Inhalt entdeckt, ist wiederum ein hohes Ranking wahrscheinlich.
Um den Crawlern die Arbeit zu erleichtern, sind auch XML- oder HTML-Sitemaps eine gängige Lösung. Sie enthalten die komplette Linkstruktur einer Website, sodass eine Suchmaschine alle Unterseiten problemlos finden und indizieren kann.
Nicht zu unterschätzen ist auch die korrekte Verwendung von HTML-Tags. Durch eine konsequente Verwendung dieser Strukturen kann man Bots helfen, den Inhalt einer Seite richtig zu interpretieren. Hierzu zählt zum Beispiel eine standardgemäße Nutzung von Überschriften (h1, h2, h3 usw.), Link-Titeln (title) und Bild-Beschreibungen (alt).
Weiterhin ist der Verzicht auf Java- oder Flash-Inhalte ratsam. Zwar ist Google inzwischen in der Lage, JavaScript Seiten zu crawlen, allerdings nimmt dies viel Crawling-Budget in Anspruch. Stattdessen sollten serverseitige Sprachen wie PHP oder ASP verwendet werden, um Navigationselemente und andere Bestandteile der Website in HTML zu erzeugen. Der Client (Webbrowser oder Bot) benötigt kein Plug-in, um HTML-Ergebnisse zu verstehen und zu indizieren.
Eine zeitgemäße Website sollte außerdem nicht mehr auf Frames basieren, sondern sämtliche designtechnischen Aspekte mit CSS lösen. Seiten, die heute noch Frames nutzen, werden nur teilweise indiziert und von Suchmaschinen missinterpretiert.
Ein weiterer wichtiger Aspekt hinsichtlich der Optimierung der Crawlbarkeit ist, dass Seiten, die für die Indizierung freigegeben werden sollen, nicht in der robots.txt ausgeschlossen sein und keinen „noindex“ Meta-Tag enthalten dürfen. Um zu prüfen, ob dieser Fall vorliegt, kann man auf verschiedene Tools der Suchanbieter zurückgreifen. Google beispielsweise stellt hierfür die Search Console für Webmaster zu Verfügung.
Da Cyberkriminelle immer öfter Botangriffe veranlassen, nutzen Websitebetreiber den sogenannten Botschutz. Dieses Sicherheitssystem überwacht Zugriffe auf die Website, erkennt Bots und sperrt sie bei Bedarf aus. Ein falsch konfigurierter Botschutz kann aber auch Bots von Google, Bing und anderen Suchmaschinen blockieren, was dazu führt, dass Seiten nicht mehr indiziert werden. Daher sollte sichergestellt werden, dass der Botschutz vor der Sperrung die jeweilige IP-Adresse auf den Host prüft. Auf diese Weise wird erkannt, ob der Bot zu Google, Bing oder anderen Suchmaschinen gehört.
Abschließend ist darauf hinzuweisen, dass die Crawlbarkeit auch durch die Performance einer Website beeinflusst wird. Liegt die Internetpräsenz auf einem langsamen Server oder wird sie von technischen Problemen ausgebremst, erhält sie in der Regel kein gutes Suchmaschinenranking. Wahrscheinlich wird ein Teil der Unterseiten gar nicht indiziert, da Bots abspringen, wenn eine Seite zu lange lädt. Daher ist eine schnelle Infrastruktur die Grundlage für wirkungsvolle SEO.
Im Folgenden haben wir die soeben erläuterten Punkte nochmals in Form einer kurzen Checkliste für Sie zusammengefasst:
- gute interne Verlinkung
- XML- oder HTML-Sitemap
- korrekte Verwendung von HTML-Tags
- Verzicht auf Java- oder Flash-Inhalte
- Verzicht auf Frames
- Überprüfung der durch robots.txt und "noindex" ausgeschlossenen Seiten
- richtige Konfiguration des Botschutzes
- schnelle Performance
Weiterführende Links
Ähnliche Artikel
| Über den Autor |
 |