Inverse Dokumenthäufigkeit: Unterschied zwischen den Versionen
| Zeile 16: | Zeile 16: | ||
Die inverse Dokumenthäufigkeit wird mit einer Formel berechnet. Diese Formel vergleicht die Häufigkeit, mit der verschiedene Wörter in einer großen Anzahl von Dokumenten verwendet werden. So erhält jeder Term ein IDF-Gewicht, das angibt, wie wichtig ein bestimmtes Wort ist. Die für diese Berechnung verwendete Formel lautet wie folgt: | Die inverse Dokumenthäufigkeit wird mit einer Formel berechnet. Diese Formel vergleicht die Häufigkeit, mit der verschiedene Wörter in einer großen Anzahl von Dokumenten verwendet werden. So erhält jeder Term ein IDF-Gewicht, das angibt, wie wichtig ein bestimmtes Wort ist. Die für diese Berechnung verwendete Formel lautet wie folgt: | ||
| − | [[File:Formel IDF.PNG|link=|border|250px|alt=Inverse Dokumenthäufigkeit|IDF Formel als Teil von WDF*IDF]] | + | [[File:Formel IDF.PNG|link=|border|250px|alt=Inverse Dokumenthäufigkeit Formel|IDF Formel als Teil von WDF*IDF]] |
N<sub>D</sub> = Gesamtzahl der Seiten | N<sub>D</sub> = Gesamtzahl der Seiten | ||
Version vom 23. August 2021, 12:41 Uhr
Inhaltsverzeichnis
Was ist inverse Dokumenthäufigkeit?
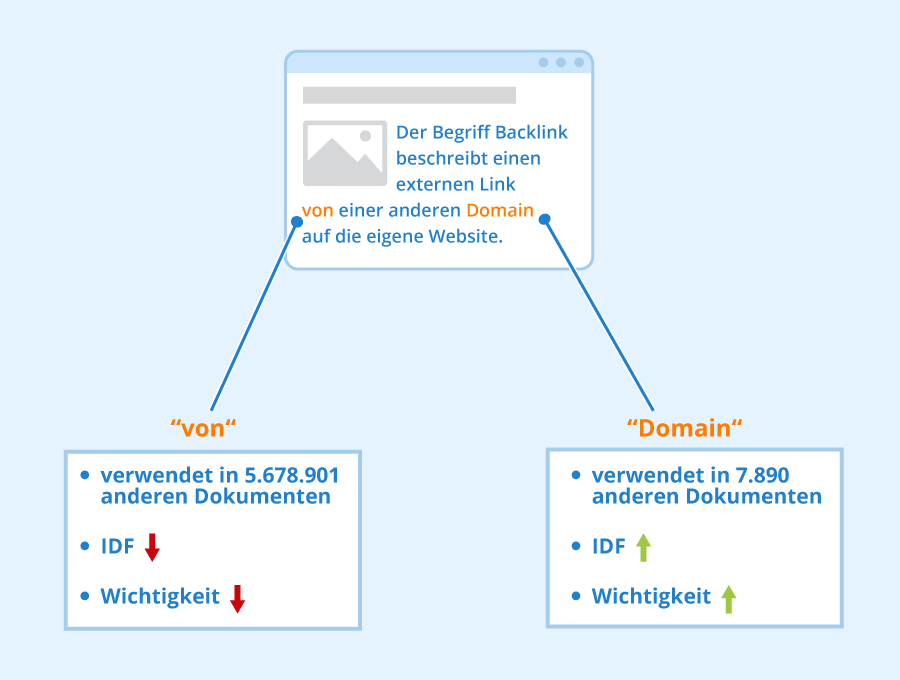
Die inverse Dokumenthäufigkeit, auch IDF genannt, ist eine Methode zur Messung der Einzigartigkeit eines Terms, der in einem Dokument verwendet wird. IDF betrachtet die Häufigkeit, mit der ein Term in anderen Dokumenten einer Datenbank verwendet wird, und schreibt Wörtern, die weniger häufig verwendet werden, einen höheren Wert zu. IDF kann somit messen, wie viel Information ein Wort zum Inhalt eines Dokuments beiträgt.
Neben vielen weiteren Anwendungsfällen kann IDF dazu verwendet werden, unwichtige Wörter aus einem Text herauszufiltern und Computerprogramme beim Filtern und Ordnen von Dokumenten zu unterstützen, indem die Relevanz eines Dokuments anhand der Wichtigkeit bestimmter Wörter bewertet wird.
Im Deutschen liefern gebräuchliche Wörter wie ein/der/die/das/ist/in nicht viele Informationen, obwohl sie für die Bildung korrekter und verständlicher Sätze wichtig sind. Da diese Wörter, auch Stoppwörter genannt, in fast allen deutschen Dokumenten/Websites häufig vorkommen, kann IDF helfen, diese Wörter herauszufiltern, indem ihnen eine sehr geringe Bedeutung zugewiesen wird.
Wörter, die seltener sind, werden hingegen als wichtiger angesehen und erhalten daher einen höheren Wert. IDF wird oft in Kombination mit anderen Methoden zur Bewertung der Relevanz von Dokumenten/Websites in Sortieralgorithmen verwendet. Sie wird auch in Kombination mit der Termfrequenz (TF) für die Optimierung von Inhalten für SEO-Zwecke verwendet, wie weiter unten in diesem Artikel erklärt wird.
Wie funktioniert die inverse Dokumenthäufigkeit?
Die inverse Dokumenthäufigkeit wird mit einer Formel berechnet. Diese Formel vergleicht die Häufigkeit, mit der verschiedene Wörter in einer großen Anzahl von Dokumenten verwendet werden. So erhält jeder Term ein IDF-Gewicht, das angibt, wie wichtig ein bestimmtes Wort ist. Die für diese Berechnung verwendete Formel lautet wie folgt:

ND = Gesamtzahl der Seiten
fi = Anzahl der Seiten, die den Term i beinhaltet
Wofür kann die inverse Dokumenthäufigkeit verwendet werden?
Die inverse Dokumenthäufigkeit ist eine Methode, mit der bestimmt werden kann, wie wichtig ein Wort ist oder wie einzigartig ein Dokument ist. Sie wird bei der Informationsgewinnung (Information Retrieval –IR) verwendet. Information Retrieval ist die Suche nach einem relevanten Dokument/einer relevanten Seite oder nach anderweitig relevanten Informationen in einer größeren Datenbank von Dokumenten/Seiten. IR ist ein wichtiger Teil des maschinellen Lernens und der Keyword-Extraktion. Durch das Verständnis der Wichtigkeit eines Terms kann es deutlich einfacher werden, Millionen von Dokumenten zu filtern, um die – basierend auf dem gesuchten Term und anderen relevanten Wörtern – wichtigsten zu finden.
IDF versus Termfrequenz
Der Hauptunterschied zwischen Termfrequenz und IDF liegt darin, dass die Termfrequenz allein nicht die Bedeutung eines Terms berücksichtigt. IDF konzentriert sich auf die Bedeutung von Wörtern in einem Dokument/auf einer Seite basierend auf der Einzigartigkeit im Vergleich zu anderen Dokumenten/Seiten. Beide Methoden wurden bei der Information Retrieval eingesetzt, werden aber meist in Kombination verwendet, um eine effektivere Informationssuche zu ermöglichen.
Inverse Dokumenthäufigkeit und WDF-IDF
IDF ist ein Teil der WDF-IDF-Methode zum Ermitteln relevanter Informationen aus einem Index/einer Datenbank. WDF-IDF kombiniert die Termfrequenz und die inverse Dokumenthäufigkeit, um die relevantesten Informationen in einer Datenbank/einem Index zu finden. Dies kann ein Dokumentindex oder ein Website-Index sein, aber es kann sich auch um andere Formen von Daten handeln.
Unter Berücksichtigung von Bedeutung und Häufigkeit der Terme ordnet WDF-IDF den Wörtern Werte zu, mit deren Hilfe Sortieralgorithmen große Informationsmengen effektiver sortieren können.
Bedeutung für SEO
IDF ist ein nützliches SEO-Werkzeug, wenn es richtig verwendet wird. Die Methode kann (in Kombination mit der Termfrequenz) bei der Extraktion wichtiger Keywords sowie bei der Erstellung einzigartiger und relevanter Inhalte eingesetzt werden. WDF-IDF ermöglicht es, den Inhalt der eigenen Webseite mit den Inhalten anderer Webseiten zu vergleichen, die zu einem bestimmten Keyword ranken. Dies erleichtert die Optimierung der eigenen Inhalte. Unser WDF*IDF-Tool unterstützt bei dieser Aufgabe, indem es die WDF*IDF-Werte berechnet und anzeigt, welche Terme zu einem Text hinzugefügt oder entfernt werden sollten.

Screenshot von Seobilitys WDF*IDF-Tool für die Content Optimierung
Weiterführende Links
Ähnliche Artikel