ASCII-Code: Unterschied zwischen den Versionen
(→Ähnliche Artikel) |
|||
| Zeile 377: | Zeile 377: | ||
} | } | ||
</script></html> | </script></html> | ||
| + | |||
| + | {| class="wikitable" style="text-align:left" | ||
| + | |- | ||
| + | |'''Über den Autor''' | ||
| + | |- | ||
| + | | [[File:Seobility S.jpg|link=|100px|left|alt=Seobility S]] Das Seobility Wiki Team besteht aus SEO-, Online-Marketing- und Web-Experten mit praktischer Erfahrung in den Bereichen Suchmaschinenoptimierung, Online-Marketing und Webentwicklung. Alle unsere Artikel durchlaufen einen mehrstufigen Redaktionsprozess, um Dir die bestmögliche Qualität und wirklich hilfreiche Informationen bieten zu können. <html><a href="https://www.seobility.net/de/wiki/Seobility_Wiki_Team" target="_blank">Mehr Informationen über das Seobility Wiki Team</a></html>. | ||
| + | |} | ||
| + | |||
| + | <html><script type="application/ld+json"> | ||
| + | { | ||
| + | "@context": "https://schema.org", | ||
| + | "@type": "Article", | ||
| + | "author": { | ||
| + | "@type": "Organization", | ||
| + | "name": "Seobility", | ||
| + | "url": "https://www.seobility.net/" | ||
| + | } | ||
| + | } | ||
| + | </script></html> | ||
Aktuelle Version vom 23. Januar 2024, 13:57 Uhr
Inhaltsverzeichnis
Definition
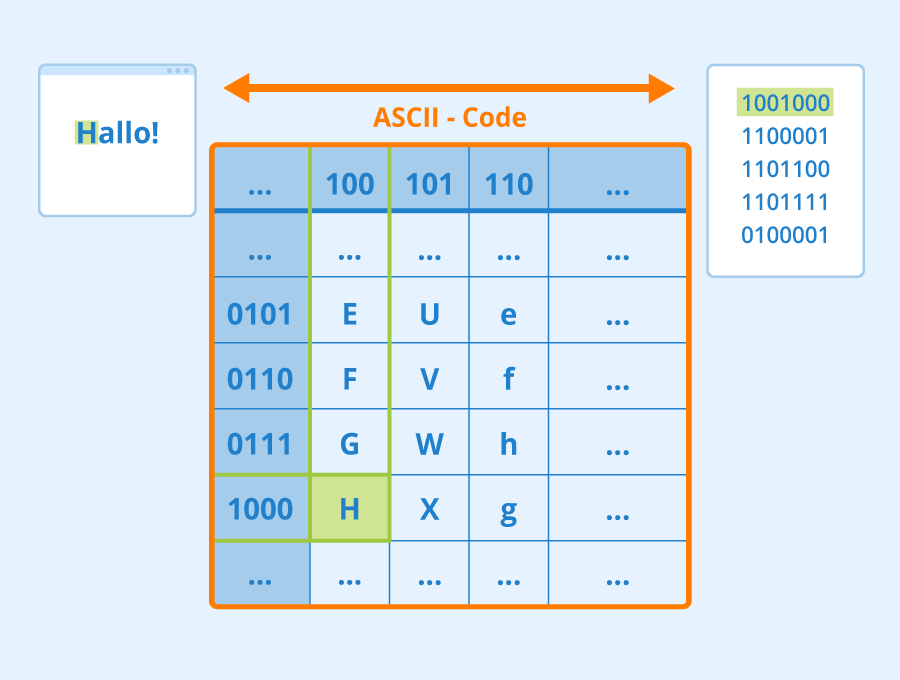
ASCII steht für "American Standard Code for Information Interchange" und bezeichnet einen Zeichensatz-Standard für Textdaten und den Informationsaustausch. Zeichenkodierungen (auch Codepages genannt) definieren, wie Buchstaben und sonstige Textzeichen sowie Steuercodes für den Datentransfer in Bits und Bytes zu codieren sind.
Der ASCII-Code ist neben Unicode, ISO-8859-1 und Windows-1252 einer der wichtigsten Zeichensatz-Standards. Der Code war für eine lange Zeit der dominierende Standard für Webseiten, bis er 2007 von der Unicode-Codierung UTF-8 überholt wurde. Dennoch ist er auch heute noch relevant, da es immer noch Bereiche gibt, in denen nur Zeichen erlaubt sind, die der ASCII-Code enthält.
Geschichte
Der ASCII Code blickt auf eine lange Geschichte zurück. Seine Anfänge liegen in der Telegrafie und dem Morse-Code sowie dem 5-Bit-Murray-Code, den der neuseeländische Erfinder Donald Murray zwischen 1901 und 1932 entwickelte. Die erste Version des ASCII Codes wurde 1963 von der ASA, der American Standards Association, herausgebracht. Die ASA war ein Vorläufer des American National Standards Institute (ANSI), dem US-amerikanischen Gegenstück zum Deutschen Institut für Normung (DIN). 1968 erschien die bis heute gültige Fassung des Zeichensatzes.
Der 7-Bit-ASCII-Zeichensatz
Historisch bedingt nutzt der originale ASCII Code nur sieben Bits eines üblichen 8-Bit-Bytes und kann maximal 128 verschiedene Zeichen codieren. Der Code enthält die Klein- und Großbuchstaben des englischen Alphabets, die wichtigsten Satzzeichen, mathematische Symbole sowie 33 Steuercodes für Datentransfer und Textformatierung.
Im Detail sind folgende Zeichengruppen enthalten:
- 0 - 32 und 127: Steuercodes für die Datenübertragung sowie Leerzeichen, Tabulatoren und Zeilenumbrüche
- 48 - 57: Ziffern
- 65 - 90: Großbuchstaben
- 97 - 122: Kleinbuchstaben
- 33 - 47, 58 - 64, 91 - 96 und 123 - 126: Satzzeichen, mathematische Symbole, Klammern und sonstige Schriftzeichen.
Landesspezifische Sonderzeichen wie Umlaute und Accents sind im ASCII Code nicht enthalten.
Obwohl die Anordnung chaotisch und willkürlich erscheinen mag, resultiert sie aus gründlicher Planung und Überlegung. Die Buchstaben sind so positioniert, dass sich die Groß- und Kleinschreibung nur durch ein einziges Bit unterscheidet. Ziffern, Leerzeichen und einige andere Symbole befinden sich absichtlich vor den Buchstaben, um Sortierungen zu vereinfachen. Des Weiteren liegen viele nicht alphanumerische Symbole auf Positionen, die der Anordnung auf Schreibmaschinen ähnelt.
Erweiterte Zeichensätze: ISO-8859
Da der eigentliche ASCII Code nur das englische Alphabet beinhaltet, haben sich viele regionenspezifische Erweiterungen entwickelt. Besondere Bedeutung bekamen die Zeichensätze Windows-1252 und ISO-8859-1. Beide sind 8-Bit-Erweiterungen des ursprünglichen Standards und enthalten viele regionale Sonderzeichen. Aufgrund historischer Entwicklungen werden beide Standards oft als ANSI-Zeichensätze bezeichnet. Streng genommen ist dies jedoch nicht korrekt, da das ANSI diese Zeichensätze nie offiziell normiert hat.
Da auch mit 8 Bits nur 256 Zeichen zur Verfügung stehen und somit nicht alle Sprachen abgedeckt werden können, wurde mit ISO-8859 eine Sammlung verschiedener Zeichensätze für unterschiedliche Sprachen und Regionen entwickelt. Beispielsweise enthält ISO-8859-7 das lateinische und griechische Alphabet, während ISO-8859-4 die Sonderzeichen der skandinavischen und baltischen Sprachen abdeckt. ISO-8859-1 beinhaltet die westeuropäischen Alphabete und ist fast deckungsgleich mit Windows-1252.
Sowohl bei Windows-1252 als auch bei ISO-8859-1 sind die ersten 128 Zeichen identisch zum ASCII Code. Ab Position 128 folgen die Codepage-spezifischen Sonderzeichen, wobei die Nummern 128 bis 159 im ISO-8859-Standard undefiniert sind. Beginnend mit Nummer 160 sind dann die Sonderzeichen der unterschiedlichen Sprachen und Regionen enthalten.
ASCII, Unicode und UTF-8
Wenngleich die ISO-8859-Standards viele Sprachen abdecken, sind lange nicht alle Sprachen enthalten. Zudem führten die unterschiedlichen Zeichensätze zu einem beträchtlichen Durcheinander, da sie nicht miteinander kompatibel sind. Bereits 1988 entstanden deshalb die ersten Pläne für einen einheitlichen Unicode-Zeichensatz, dessen erste Version 1991 heraus kam.
Unicode ermöglicht die Darstellung von über einer Million Zeichen und löst nach und nach alle anderen Zeichensätze ab. Besonders wichtig ist das Unicode-Format UTF-8, welches mittlerweile das vorherrschende Textformat im World Wide Web ist. UTF-8 hat den großen Vorteil, dass es ASCII-kompatibel ist, da die ersten 128 Zeichen identisch sind.
Aufbau der ASCII- und ISO-Tabellen
Für die Darstellung der Zeichensätze kommen üblicherweise Listen oder Tabellen zum Einsatz, um die Zeichen und ihre numerischen Werte leicht auffindbar zu machen. Diese Listen geben die jeweiligen Zeichen samt ihrer dezimalen, hexadezimalen, oktalen und/oder binären Werte an.
Viele Tabellen sind hexadezimal aufgebaut und trennen die Codes in das erste und das zweite Halbbyte. Beispielsweise findet sich das große H in der ASCII-Tabelle in der 4. Zeile der 8. Spalte, woraus sich die hexadezimale Notation 0x48 ergibt. Der Wagenrücklauf CR hat den Code 0x0D, da er in Zeile 0 und Spalte D liegt. 0x ist dabei ein übliches Präfix, um auf die hexadezimale Schreibweise hinzuweisen.
ASCII-Tabelle
Im Folgenden ist die ASCII-Tabelle mit Codes in dezimaler, hexadezimaler und oktaler Schreibweise zu sehen:
|
|
|
| Zeich. | dezimal | hexadez. | oktal |
|---|---|---|---|
| ` | 96 | 0x60 | 140 |
| a | 97 | 0x61 | 141 |
| b | 98 | 0x62 | 142 |
| c | 99 | 0x63 | 143 |
| d | 100 | 0x64 | 144 |
| e | 101 | 0x65 | 145 |
| f | 102 | 0x66 | 146 |
| g | 103 | 0x67 | 147 |
| h | 104 | 0x68 | 150 |
| i | 105 | 0x69 | 151 |
| j | 106 | 0x6A | 152 |
| k | 107 | 0x6B | 153 |
| l | 108 | 0x6C | 154 |
| m | 109 | 0x6D | 155 |
| n | 110 | 0x6E | 156 |
| o | 111 | 0x6F | 157 |
| p | 112 | 0x70 | 160 |
| q | 113 | 0x71 | 161 |
| r | 114 | 0x72 | 162 |
| s | 115 | 0x73 | 163 |
| t | 116 | 0x74 | 164 |
| u | 117 | 0x75 | 165 |
| v | 118 | 0x76 | 166 |
| w | 119 | 0x77 | 167 |
| x | 120 | 0x78 | 170 |
| y | 121 | 0x79 | 171 |
| z | 122 | 0x7A | 172 |
| { | 123 | 0x7B | 173 |
| 124 | 0x7C | 174 | |
| } | 125 | 0x7D | 175 |
| ~ | 126 | 0x7E | 176 |
| DEL | 127 | 0x7F | 177 |
ASCII-Code, Unicode und SEO
Obwohl ASCII und ISO-8859 lange Zeit die vorherrschenden Textzeichen-Standards waren, gelten sie heute im Web als veraltet. Die offizielle Standardisierungs-Organisation W3C (World Wide Web Consortium) empfiehlt die ausschließliche Verwendung von UTF-8 als Zeichensatz-Codierung für alle Webseiten.
Außer in den eigentlichen Webseiten-Texten lässt sich Unicode ebenfalls nutzbringend in den Meta Descriptions einsetzen. Mithilfe von Unicode-Zeichen wie Häkchen, Herzen, Sternen, Briefumschlägen oder Währungssymbolen können hier beim Leser unbewusste Impulse ausgelöst werden. Beispielsweise erzeugen Häkchen und Herzen Zustimmung, während Briefumschläge und Telefonsymbole zur Kontaktaufnahme animieren. Das hat zwar keinen direkten Einfluss auf das Suchmaschinenranking, erhöht jedoch die Klickrate und führt zu mehr Besuchern und Kunden.

Screenshot einer Meta-Description mit Sonderzeichen von google.de
In SEO-relevanten Keywords und Keyword-Phrasen ist hingegen etwas Zurückhaltung angeraten. Landesspezifische Buchstaben wie Umlaute und Accents stellen kein Problem dar. Ungewöhnliche Sonderzeichen, Trennsymbole, Emoticons und Piktogramme können die Keyword-Erkennung jedoch unmöglich machen.
Ähnliche Artikel
| Über den Autor |
 |