Punycode: Unterschied zwischen den Versionen
(→Ähnliche Artikel) |
|||
| Zeile 56: | Zeile 56: | ||
} | } | ||
</script></html> | </script></html> | ||
| + | |||
| + | {| class="wikitable" style="text-align:left" | ||
| + | |- | ||
| + | |'''Über den Autor''' | ||
| + | |- | ||
| + | | [[File:Seobility S.jpg|link=|100px|left|alt=Seobility S]] Das Seobility Wiki Team besteht aus SEO-, Online-Marketing- und Web-Experten mit praktischer Erfahrung in den Bereichen Suchmaschinenoptimierung, Online-Marketing und Webentwicklung. Alle unsere Artikel durchlaufen einen mehrstufigen Redaktionsprozess, um Dir die bestmögliche Qualität und wirklich hilfreiche Informationen bieten zu können. <html><a href="https://www.seobility.net/de/wiki/Seobility_Wiki_Team" target="_blank">Mehr Informationen über das Seobility Wiki Team</a></html>. | ||
| + | |} | ||
| + | |||
| + | <html><script type="application/ld+json"> | ||
| + | { | ||
| + | "@context": "https://schema.org", | ||
| + | "@type": "Article", | ||
| + | "author": { | ||
| + | "@type": "Organization", | ||
| + | "name": "Seobility", | ||
| + | "url": "https://www.seobility.net/" | ||
| + | } | ||
| + | } | ||
| + | </script></html> | ||
Aktuelle Version vom 23. Januar 2024, 17:45 Uhr
Inhaltsverzeichnis
Definition
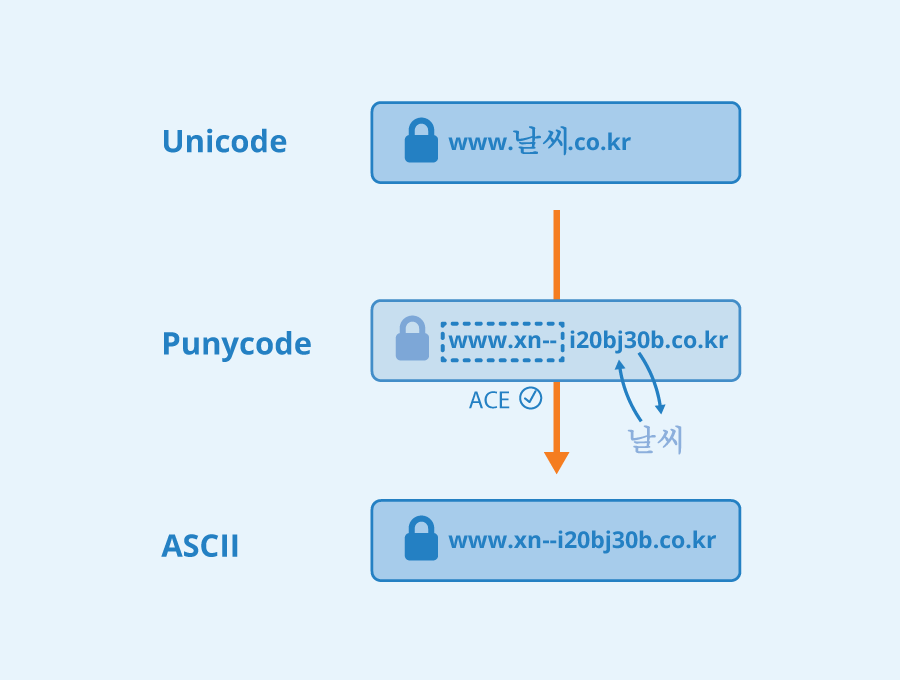
Punycode ist ein in RFC 3492 definiertes, standardisiertes Kodierungsverfahren zur Darstellung von Unicode mit der begrenzten ASCII-Zeichenteilmenge, die für eine Domain verwendet werden kann. Mit Punycode werden die Namen von Domains, die Unicode-Zeichen enthalten, in eine Teilmenge von ASCII transcodiert, die aus den Buchstaben a bis z, den Ziffern 0 bis 9 und dem Bindestrich besteht. Diese zulässigen Zeichen werden als Basiszeichen bezeichnet.
Hintergrund
Das ursprüngliche Internet basierte ausschließlich auf dem ASCII Zeichensatz. Der Grund dafür ist, dass das Internet in den USA entwickelt wurde. Englisch ist eine Sprache, bei der jeder Name und jeder Text mit Zeichen aus dem ASCII-Satz geschrieben werden kann.
Die meisten Sprachen der Welt erfordern für die Darstellung von Text jedoch weitere Zeichen, die nicht in ASCII enthalten sind. Dies hat zu Dutzenden verschiedener Zeichensätze - oder Codierungen - in anderen Ländern und Regionen geführt. Aus der Vereinigung all dieser Kodierungen ist Unicode hervorgegangen. Heute sind die meisten nicht-englischen Seiten im Web und viele der englischen in Unicode geschrieben. Dadurch wurde die Frage aufgeworfen, warum für eine Domain immer noch nur ASCII-Buchstaben und -Ziffern sowie das Bindestrich-Zeichen verfügbar waren. Dies führte schließlich zu der Entwicklung von Punycode, der im Jahr 2003 von der IETF (Internet Engineering Task Force) für die Kodierung internationalisierter Domainnamen in Anwendungen (IDNA) standardisiert wurde.
Mithilfe von Punycode können sogenannte “internationalisierte Domainnamen” (IDN) verwendet werden. Eine IDN ist eine Domain, deren Name zu den aus dem lateinischen Alphabet stammenden Basiszeichen zusätzlich Sonderzeichen, beispielsweise die Umlaute ä, ö, ü im deutschen Sprachraum oder Schriftzeichen anderer Alphabete enthält. Diese Sonderzeichen können vom Domain Name System (DNS) nicht verarbeitet werden. Die Punycode-Syntax codiert die Unicode-Zeichen internationalisierter Domainnamen in die vom DNS bevorzugte ASCII-Teilmenge.
Beispiel für die Codierung einer IDN mit Punycode
Internationalisierte Domains, deren Namen Umlaute enthalten, wie beispielsweise www.bäckerei-müller.de, können vom DNS ohne Umcodierung nicht verarbeitet werden. Nach der Codierung in den limitierten ASCII-Zeichensatz mithilfe des Punycode Kodierungsverfahrens lautet der Name www.xn-bckerei-mller-bfb28a.de. Die Label www. und .de sowie die im lateinischen Alphabet enthaltenen Zeichen bleiben bei der Codierung erhalten. Die Umlaute ä und ü wurden entfernt. Die Buchstaben-/Ziffernfolge vor .de enthält die Information, an welcher Stelle welcher Umlaut im Namen enthalten ist, sodass die Codierung wieder umgekehrt werden kann.
Die Funktionsweise des Punycode
Der dem Punycode zugrunde liegende Bootstring-Algorithmus ermöglicht es, eine Zeichenkette aus beliebigen Zeichensätzen mit dem begrenzten, für Domains zulässigen ASCII-Zeichensatz eindeutig darzustellen. Das Punycode Kodierungsverfahren beruht auf sechs Grundprinzipien.
- Vollständigkeit: Vollständigkeit bedeutet, dass jeder denkbare Text durch eine einfache Zeichenkette abgebildet werden kann.
- Eindeutigkeit: Eindeutigkeit besagt, dass jeder ASCII-Zeichenkette genau ein Punycode zugeordnet werden kann und umgekehrt.
- Reversibilität: Reversibilität bedeutet, dass die Kodierung ohne Verlust von Informationen wieder umgekehrt werden kann.
- Effizienz: Die Effizienz soll sicherstellen, dass die kodierte Zeichenkette im Optimalfall nicht oder nur unwesentlich länger als die ursprünglich Zeichenkette ist.
- Einfachheit: Es werden einfache Algorithmen für die Kodierung und Dekodierung von Text genutzt.
- Lesbarkeit: Nur die Zeichen im Text, die sich nicht in ASCII darstellen lassen, werden neu codiert. Alle anderen Zeichen bleiben unverändert und werden an ihrer ursprünglichen Position übernommen.
Punycode vollzieht in einem ersten Schritt eine Normalisierung der Zeichenkette. Das bedeutet, dass alle Großbuchstaben durch Kleinbuchstaben ersetzt werden. Zudem werden die sogenannten Ligaturen, wie das im deutschen Sprachraum gebräuchliche "ß", in einzelne Zeichen, in diesem Fall "ss", aufgelöst. Anschließend werden alle Zeichen in der Zeichenkette, die nicht zu den zulässigen Basiszeichen gehören, gelöscht und in codierter Form, durch einen Bindestrich getrennt, an den Namen der Domain angehängt. Im Beispiel www.xn-bckerei-mller-bfb28a.de ist dies die Buchstaben-/Ziffernfolge -bfb28a.
Dem Ergebnisstring wird bei der Punycode Kodierung ein sogenanntes ACE-Präfix vorangestellt. Die Abkürzung steht für "ASCII Compatible Encoding" und bedeutet ASCII-kompatible Kodierung. Das ACE-Präfix ist das “xn” im Beispiel. Durch dieses Präfix wird sichergestellt, dass Domainnamen mit einem darin enthaltenen Bindestrich nicht als IDN angesehen werden. Die Buchstabenkombination xn wurde als Präfix gewählt, weil sie so gut wie nie in einem Text vorkommt.
Domains, deren Namen ausschließlich Unicode Zeichen und keine ASCII-Zeichen beinhalten, wie dies beispielsweise bei Domains mit kyrillischen oder griechischen Zeichen der Fall sein kann, enthalten nach der Codierung nur das ACE-Präfix und die Buchstaben-/Ziffernfolge mit den codierten Zeichen.
Weiterführende Links
Ähnliche Artikel
| Über den Autor |
 |