Zeichenkodierung
Inhaltsverzeichnis
Definition
Um Buchstaben, Ziffern und Symbole darzustellen, benötigt ein Computer eine Zeichenmenge, die Zeichenvorrat (engl. character repertoire) genannt wird. Für den Gebrauch in der Praxis ist diese Zeichenmenge in einer bestimmten Reihenfolge geordnet und nummeriert. Diese geordnete Zeichenmenge wird als Zeichensatz (engl. character set) bezeichnet. Damit der Computer die Zeichen richtig erkennt, werden diese außerdem durch ein Muster aus Bits beschrieben, welches die Zeichenkodierung bzw. Zeichensatzkodierung (engl. character encoding) darstellt. Da der Zeichensatz bereits eine bestimmte Reihenfolge und Nummerierung vorgibt, müssen die Bitmuster hierfür nur noch den Zeichen zugeordnet werden.
Zeichenkodierung prüfen
Prüfe die Angaben zur Zeichenkodierung auf Deiner Seite
Die Zeichensatzkodierung kommt beispielsweise bei HTML-Dokumenten zum Einsatz, da diese mit einer bestimmten Zeichensatzkodierung gespeichert werden. Dadurch ist eine eindeutige Zuordnung von Buchstaben, Ziffern und Symbolen eines Zeichensatzes möglich. Die Information über die Form der Kodierung, die für diese Datei verwendet wurde, wird beim Öffnen an den Browser oder einen anderen Benutzeragenten gesendet, damit die Bits und Bytes richtig interpretiert werden können. Wenn die deklarierte Zeichenkodierung nicht mit der tatsächlich verwendeten übereinstimmt, kann der Browser den Inhalt der Webseite nicht richtig darstellen und auch Suchmaschinen können mit diesen Seiten nichts anfangen.
Warum unterschiedliche Zeichensätze notwendig sind
Die Auswahl einer Kodierung bestimmt den Bereich von Zeichen, die auf einer Webseite verwendet werden können. Normale lateinische Buchstaben stellen dabei selten ein Problem dar, aber einige Sprachen benötigen mehr Buchstaben als andere oder verwenden Characters wie Punkte, Häkchen, Striche, Kreise oder Bögen oberhalb oder unterhalb der Buchstaben.
Dies kann schnell zu Problemen führen, wenn ein Schriftzeichen benötigt wird, das von der gewählten Kodierung nicht dargestellt werden kann. In diesem Fall muss auf eine symbolische Umschreibung (Entitätsreferenz) zurückgegriffen werden. So stellt zum Beispiel die Entitätsreferenz © das Symbol © dar. Entitätsreferenzen beginnen mit einem "&" und enden mit einem Semikolon ";". Die Verwendung von Referenzen funktioniert zwar meistens relativ gut, das Verfahren benötigt jedoch mehr Bytes, erschwert das Markup und führt oft zu Schreibfehlern, weshalb deren Gebrauch auf ein Minimum beschränkt werden sollte.
Welche Kodierung sollte gewählt werden?
Für eine englischsprachige Webseite genügt der Zeichensatz US-ASCII, wenn auf eine typografisch korrekte Zeichensetzung, wie zum Beispiel geschweifte Anführungszeichen, verzichtet werden kann. Bei anderen europäischen Sprachen wie Deutsch, Französisch oder Spanisch, funktioniert der Zeichensatz ISO 8859-1 sehr gut, weshalb er zu einem De-facto Standard für Westeuropa geworden ist. Zeichensätze mit polnischen, tschechischen, kyrillischen oder griechischen Characters können eine andere Version aus ISO 8859 wählen. Selbst die Kodierung hebräischer, arabischer und orientalischer Zeichen auf einer Webseite stellt kein Problem dar, wenn die Zeichensatzkodierung UTF-8 ausgewählt wurde. Die Abkürzung steht für UCS Transformation Format - 8 Bit, wobei UCS wiederum die Abkürzung für Universal Character Set ist.
UTF-8 ist mittlerweile die am häufigsten verwendete Zeichenkodierung. Sie verwendet die Code-Tabelle des Unicode Systems, welches die Zeichen und Elemente aller bekannten Schriftkulturen enthält, die von Linguisten ermittelt wurden. Die Nummern der Zeichen werden bei Unicode durch eine zwei Byte große Zahl dargestellt. Auf diese Weise lassen sich bis zu 65536 Zeichen in dieser Tabelle unterbringen. Aus diesem Grund ist UTF-8 der im Internet am häufigsten verwendete Zeichensatz.
Im Grunde wäre es also sinnvoll, immer UTF-8 zu verwenden anstatt sich mit Entitäten herumschlagen zu müssen. Leider ist dies jedoch nicht immer möglich, denn nicht alle Editoren unterstützen UTF-8. Hinzu kommt, dass einige ältere Browser kein UTF-8 verstehen, wobei dieses Problem heute eher selten auftreten sollte.
Die Angabe der Zeichensatzkodierung im Dokument
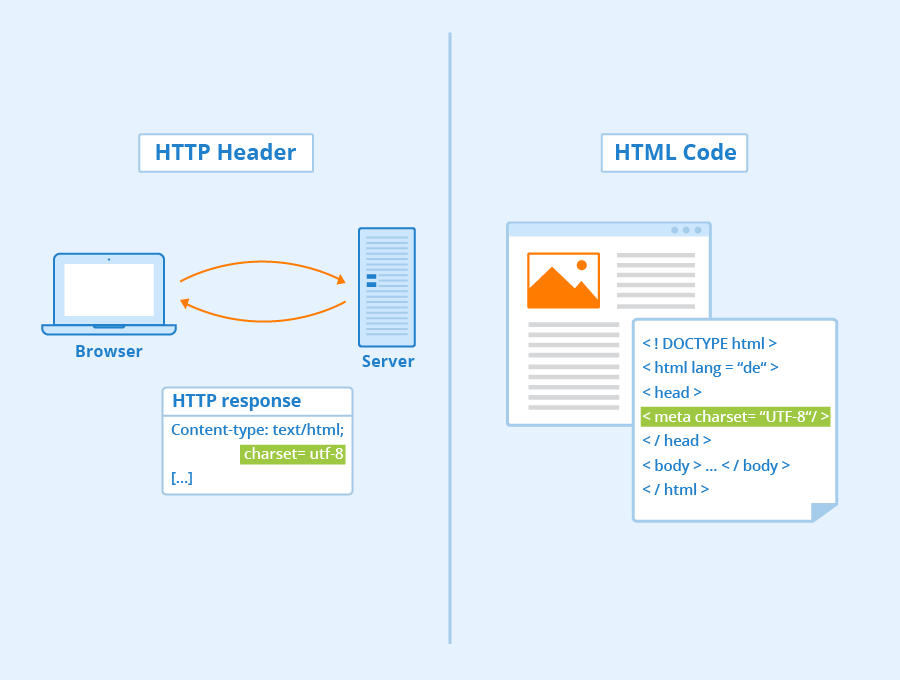
Sobald man sich für eine Kodierung entschieden hat, muss sichergestellt werden, dass die richtigen Informationen an den Browser und an die Suchmaschine weitergegeben werden. In jedem HTML-Dokument ist die Angabe der verwendeten Zeichenkodierung Pflicht. Hierfür kann entweder der HTTP-Header oder das HTML-Markup genutzt werden.
Angabe im HTTP-Header
Webseiten werden über das HyperText Transfer Protocol (HTTP) zur Anzeige bereitgestellt. Ein Browser sendet über HTTP eine Anfrage und der Server sendet die Antwort über HTTP zurück. Die Antwort besteht aus zwei Teilen: Dem HTTP-Header und dem Körper, die durch eine Leerzeile getrennt sind. Die Kopfzeichen enthalten die Informationen über den Körper (Inhalt). Der Körper besteht dann aus der angeforderten Ressource, in der Regel ein HTML-Dokument. Die Kodierungsinformationen für das Dokument werden vom Webserver im Content Type Header gesendet:
Content-Type: text/html; charset=utf-8
Angabe im HTML-Markup
Wenn das HTTP-Äquivalent in HTML bereitgestellt werden soll, kann dazu ein Meta-Element im HEAD-Abschnitt des Dokuments verwendet werden:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Alternativ kann auch folgendes Meta-Element angegeben werden:
<meta charset="utf-8">
Beispiel für die Angabe der Zeichensatzkodierung im HTML-Markup:

Screenshot mit Zeichensatzkodierung im HTML Code von seobility.net
Es sollte jedoch beachtet werden, dass jeder echte HTTP-Header ein Meta-Element überschreibt, weshalb der Webserver unbedingt korrekt eingerichtet werden muss. Bei einem Apache-Server wird hierfür folgender Code in die Konfigurationsdatei geschrieben:
AddDefaultCharset UTF-8
Für Microsoft IIS muss diese Einstellung in zahlreichen Dialogfeldern vorhanden sein.
Für XML sollte die Kodierung im Kopf der Datei angegeben werden. XML unterstützt nur UTF-8 und UTF-16, was die Auswahl stark vereinfacht:
<?xml version="1.0" encoding="utf-8"?/>
Zusammenfassung
Für die richtige Darstellung eines HTML-Dokuments ist die Wahl der richtigen Zeichenkodierung unerlässlich. Wird ein Zeichensatz gewählt, der für eine Website ungeeignet ist, wie zum Beispiel ISO 8859-1 für eine chinesische Website, müssen viele Entitäten verwendet werden, was die Dateigröße unnötig vergrößert.
Bei mehrsprachigen Websites sollte deshalb unbedingt UTF-8 verwendet werden. UTF-8 und die ISO 8859er Serie werden von allen modernen Browsern unterstützt. Die meisten Browser unterstützen auch einige andere Kodierungen, aber wenn eine exotische Kodierung gewählt wird, läuft man Gefahr, dass einige Besucher, darunter auch Suchmaschinen, den Inhalt nicht lesen können.
Weiterführende Links
- http://webkrauts.de/artikel/2006/zeichens%C3%A4tze-und-zeichenkodierungen
- https://www.w3.org/International/questions/qa-what-is-encoding.de
Ähnliche Artikel