Root Directory
Definition
The root directory is a directory in Unix-like operating systems that contains all other directories and files on a system and is marked by a slash (/). The file system is the hierarchy of directories used to organize files on a computer. The use of the word "root" in this context results from the fact that the root directory at the top can be illustrated as the "root" of an upside-down tree structure.
However, in some operating systems, such as MS-DOS and various versions of Microsoft Windows, there is no single root directory, because these operating systems use a separate root directory for each storage device and partition, i.e. for each logically independent section of the hard disk drive. The A directory is usually the floppy disk drive. C is the name for the first partition of the hard disk, D for the second partition or another drive of the system, and so on.
Root directory of a website
The root directory, also known as the document root, web root, or site root directory, is the publicly accessible base folder of a website. This folder contains the index file (index.php, index.html or default.html) and is often named public_html, htdocs, www or wwwroot. How the root folder of a specific website is named depends on the web host and the settings chosen.
The root directory is the folder that is accessed when internet users type the domain name of a website into the search bar of their browser. When a website with an index.html file in the root directory is called up, the index.html file is displayed in the browser. However, a website can also store files outside the public root directory. Such files cannot be accessed via a URL or web address. They can only be accessed by the web application itself, server-side programming, or code. The prerequisite for this, however, is that access rights have been set accordingly.
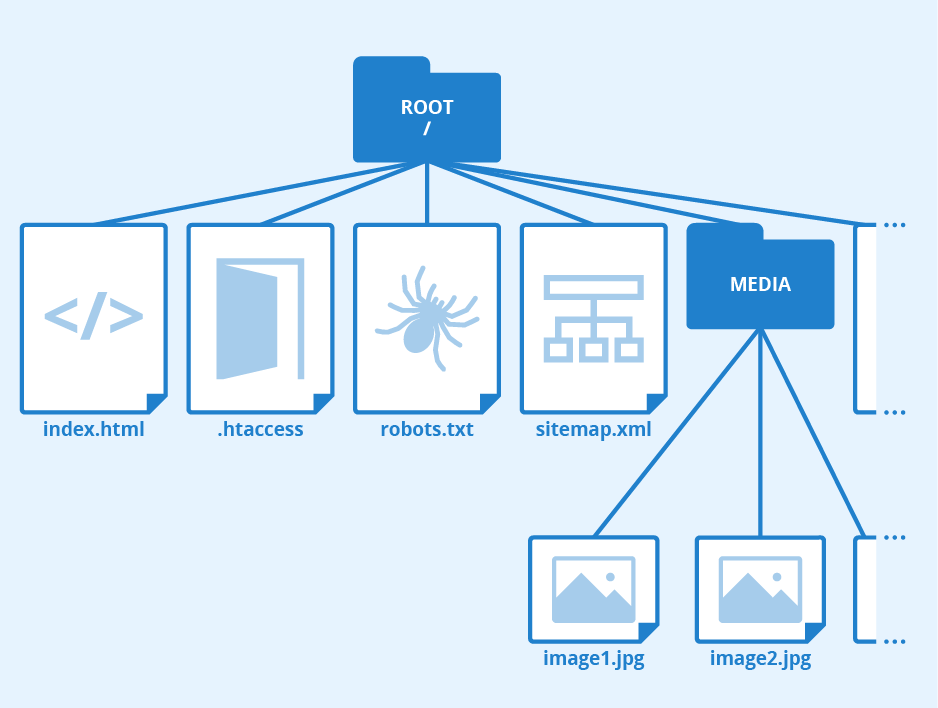
A directory system of a simple HTML website could look like this:
example/ Application/ | Library/ | Templates/ | +-- config.php public_html/ +-- Media/ | +-- image1.jpg | +-- image2.jpg --- includes/ | +-- style.css | +-- script.js +-- index.php
In the above example, the public_html folder is the root directory of the website and the index.html file is executed when someone navigates to the homepage of the site (www.example.com). The files and folders in the application files directory cannot be accessed publicly. They are used exclusively by the index.html file.
It is recommended to store all files that are not supposed to be publicly accessible outside the root folder. For example, these could be files that are inserted into the index file when this page is accessed or files that contain database login information and should not be publicly available. If these files are not stored in the root directory, they cannot be accessed publicly via a URL or web address.
Relevance of a root directory for search engine optimization
In the root directory of a website, the robots.txt file which is relevant for search engine optimization is stored, as is sitemap.xml for large websites. Search engine crawlers like Googlebot only search for these files in the root folder.
Robots.txt is used to control crawling access. It is an easy means to exclude certain resources such as unimportant image, style or script files from crawling by search engines.
A sitemap helps crawlers find all subpages of a website, accelerates crawling and indexing and preserves the valuable crawl budget allocated to a site by Google. In this respect, the root directory is relevant for the SEO of a website.