
¿Qué es el código ASCII?
ASCII son las siglas de “American Standard Code for Information Interchange“, lo que traducido al español significa “Código Estándar Americano para el Intercambio de Información”. Básicamente ASCII es un conjunto de caracteres alfanuméricos y signos que estandarizan el proceso de intercambio de información.
Por lo tanto, la codificación de caracteres también llamadas páginas de código, define cómo se codifican en bytes los caracteres de un texto y los códigos de control para la transferencia de datos.
Asimismo, el código ASCII es uno de los conjuntos de caracteres estándares más importantes, junto a los Unicodes ISO-8859-1 y Windows 1252. De hecho, fue el estándar dominante en todas las páginas web durante mucho tiempo, hasta que fue sustituido por el Unicode UTF-8, el cual apareció en 2007.
Aunque ya obsoleto de forma generalizada, el código ASCII se mantiene vigente en distintas áreas de la informática.
Historia
El código ASCII data su origen a principios del siglo anterior, en la época del telégrafo, el código Morse y el código Murray de 5 bits. Este último fue desarrollado por el inventor neozelandés Donald Murray entre 1901 y 1932.
La primera versión del código ASCII fue publicada en 1963 por la ASA (Asociación Estándar Americana), precursora del actual Instituto Americano de Estándares Nacionales (ANSI). Pero no fue sino hasta 1968 que se reveló la versión estandarizada de dicho sistema de codificación que se mantiene hasta la actualidad.
Conjunto de caracteres ASCII de 7 bits
El código ASCII original utiliza solo 7 bits, a diferencia de los 8 comúnmente empleados, y puede codificar un máximo de 128 caracteres distintos. Dicho conjunto contiene las letras mayúsculas y minúsculas del alfabeto inglés, los signos de puntuación de mayor uso, los símbolos matemáticos y también 33 códigos de control para la transferencia de datos y formato de texto.
Los grupos de códigos están distribuidos de la siguiente forma:
- 0-32 y 127: transferencia de datos, así como los espacios, tabulaciones y saltos de líneas.
- 48-57: dígitos.
- 65-90: letras mayúsculas.
- 97-122: letras minúsculas.
- 33- 7, 58-64, 91-96 y 123-126: signos de puntuación, símbolos matemáticos y otros caracteres especiales.
Para mantener la estandarización del código, los caracteres especiales y la diéresis o los corchetes, no se incluyen dentro del código ASCII de 7 bits. Por lo cual, este sistema de codificación se utiliza en una limitada cantidad de idiomas. Por ejemplo, la letra ñ y el signo empleado para abrir una interrogación en español (¿), no están dentro de este código.
Puede parecer una selección de caracteres arbitraria y caótica, pero lo cierto es que es el resultado de una minuciosa planificación. Por ejemplo, las letras que se colocan en mayúsculas o minúsculas únicamente difieren en un bit.
Asimismo, el conjunto ASCII también se caracteriza por ubicar los números, espacios y otros símbolos delante de las letras para simplificar la organización. Además, los símbolos que no son alfanuméricos están ubicados en posiciones similares a las usadas en las antiguas máquinas de escribir.
Conjuntos de caracteres extendidos: ISO-8859
Dado que el código ASCII contiene exclusivamente los caracteres del alfabeto inglés, se han desarrollado algunas extensiones específicas para cada región.
En este contexto, el conjunto de caracteres Windows 1252 y el ISO-8859-1 han ganado importancia por ser extensiones de 8 bits y contener mayor cantidad de caracteres especiales que son requeridos en otros idiomas y dialectos. Sobre la base del desarrollo histórico, ambos son referidos como el conjunto de caracteres ANSI, aunque sin fundamento porque el código ANSI jamás fue estandarizado.
De este modo, el conjunto ISO-8859 ha desarrollado una colección de caracteres distintos que encaja a la perfección con los diferentes lenguajes y regiones. Por ejemplo, el ISO-8859-7 contiene el alfabeto latín y el griego; el ISO 8859-4 cubre los caracteres de los lenguajes escandinavos y bálticos; el ISO-8859-1 contiene los alfabetos europeos occidentales y se considera casi idéntico al Windows 1252.
Dicho esto, tanto el Windows 1252 como el ISO 8859-1 coinciden durante los primeros 128 caracteres con los del ASCII y desde la posición 128 continúan los caracteres específicos de cada código. Mientras que los números del 128 al 159 no están definidos en el estándar ISO-8859, pero desde el número 160 se encuentran todos los caracteres de los diferentes idiomas y regiones.
EL ASCII, el Unicode y el UTF-8
A pesar de que los estándares ISO 8859 cubren una amplia gama de idiomas, no todos están incluidos, siendo además confuso navegar entre tantos conjuntos de datos que no son compatibles entre sí.
Por este motivo, desde 1968 se empezó a planificar cómo mantener la uniformidad de los Unicodes y, en 1991, se reveló su primera versión. Desde entonces, los Unicodes muestran más de un millón de caracteres y han reemplazado a muchos otros sistemas previamente usados.
Así es como surge el Unicode UTF-8, el cual codifica el formato de texto que predomina actualmente en la web. Es compatible con el ASCII ya que coinciden los primeros 128 caracteres de ambos códigos.
Estructura del ASCII y las tablas ISO
Con frecuencia se utilizan listas o tablas para exponer el conjunto de caracteres o signos, a fin de que aquellos y sus correspondientes valores numéricos sean fáciles de encontrar. Estas listas especifican los caracteres y sus valores decimales, hexadecimales, octales y/o binarios.
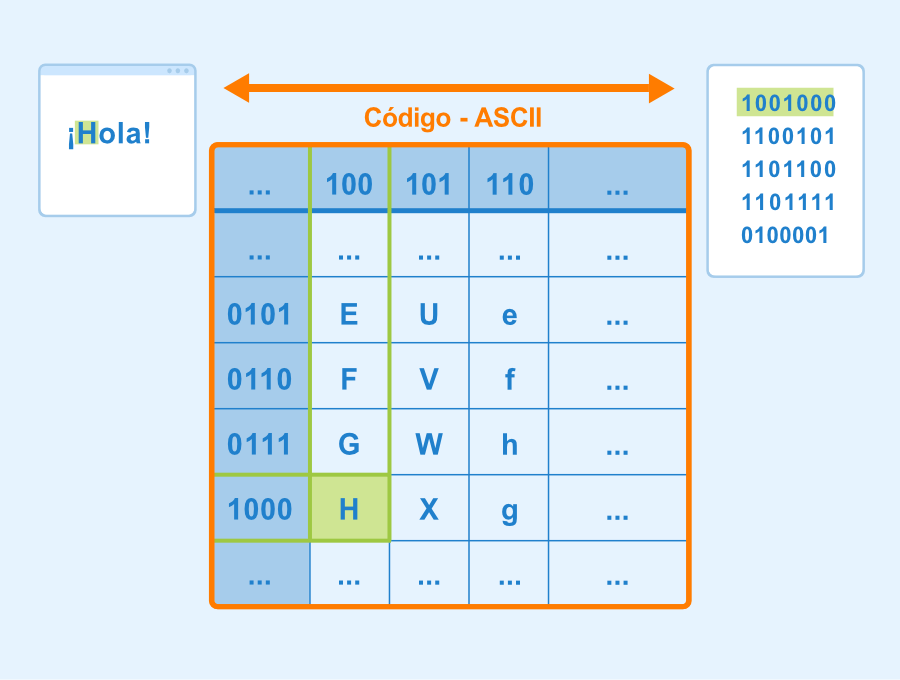
Muchas de las tablas son hexadecimales y separan los códigos dentro del primer o segundo byte. Por ejemplo, la H mayúscula se encuentra en la 4ta hilera de la 8va columna, por lo que resulta en una notación hexadecimal de 0x48.
En este sentido, el retorno de carro (CR) tiene el código 0x0D, lo que significa que se encuentra en la línea 0 y la columna D. 0x es un prefijo común dentro de la notación decimal.
Tabla ASCII
A continuación, se puede observar la tabla ASCII con los códigos de notación decimal, hexadecimal y octal:
|
|
|
| char. | decimal | hexadecimal. | octal |
|---|---|---|---|
| ` | 96 | 0x60 | 140 |
| a | 97 | 0x61 | 141 |
| b | 98 | 0x62 | 142 |
| c | 99 | 0x63 | 143 |
| d | 100 | 0x64 | 144 |
| e | 101 | 0x65 | 145 |
| f | 102 | 0x66 | 146 |
| g | 103 | 0x67 | 147 |
| h | 104 | 0x68 | 150 |
| i | 105 | 0x69 | 151 |
| j | 106 | 0x6A | 152 |
| k | 107 | 0x6B | 153 |
| l | 108 | 0x6C | 154 |
| m | 109 | 0x6D | 155 |
| n | 110 | 0x6E | 156 |
| o | 111 | 0x6F | 157 |
| p | 112 | 0x70 | 160 |
| q | 113 | 0x71 | 161 |
| r | 114 | 0x72 | 162 |
| s | 115 | 0x73 | 163 |
| t | 116 | 0x74 | 164 |
| u | 117 | 0x75 | 165 |
| v | 118 | 0x76 | 166 |
| w | 119 | 0x77 | 167 |
| x | 120 | 0x78 | 170 |
| y | 121 | 0x79 | 171 |
| z | 122 | 0x7A | 172 |
| { | 123 | 0x7B | 173 |
| 124 | 0x7C | 174 | |
| } | 125 | 0x7D | 175 |
| ~ | 126 | 0x7E | 176 |
| Borrar | 127 | 0x7F | 177 |
Los códigos ASCII, Unicodes y el SEO
Tal como y como se ha mencionado, los estándares ASCII e ISO-8859 fueron los conjuntos de caracteres predominantes por un largo periodo de tiempo, pero en la actualidad se consideran obsoletos.
La organización de estandarización oficial W3C (o Consorcio World Wide Web) recomienda el empleo exclusivo del grupo de caracteres UTF-8 para la codificación en todos los sitios web. Cabe destacar que el objetivo de la W3C es contribuir a uniformar las especificaciones técnicas de la web y no ejerce control alguno sobre el uso de los sistemas de codificación en ella empleados.
Por otra parte, la utilización de los Unicodes es recomendado dentro de los contenidos, y en las meta descripciones. El empleo de algunos símbolos especiales, si bien no presenta relevancia alguna en el posicionamiento de los buscadores, pueden incrementar la tasa de clics de una página web.
Se ha descubierto que símbolos como abrazos, corazones y estrellas incluidos en los Unicodes, desencadenan reacciones inconscientes favorables en las lectoras o lectores. Por ejemplo, los símbolos de verificación o los corazones generan aprobación, mientras que los teléfonos y los sobres son reconocidos como métodos de contacto.

Screenshot mostrando una meta descripción y un meta título que incluye caracteres especiales en google.com.
Sin embargo, en las palabras clave relevantes para el SEO se recomienda cautela en el empleo de caracteres especiales. Se admite el uso de letras especiales, diéresis o acentos, pero los caracteres como símbolos de separación, emojis o pictogramas puedan causar que una keyword sea irreconocible.
