Bingbot
Inhaltsverzeichnis
Was ist der "Bingbot"?
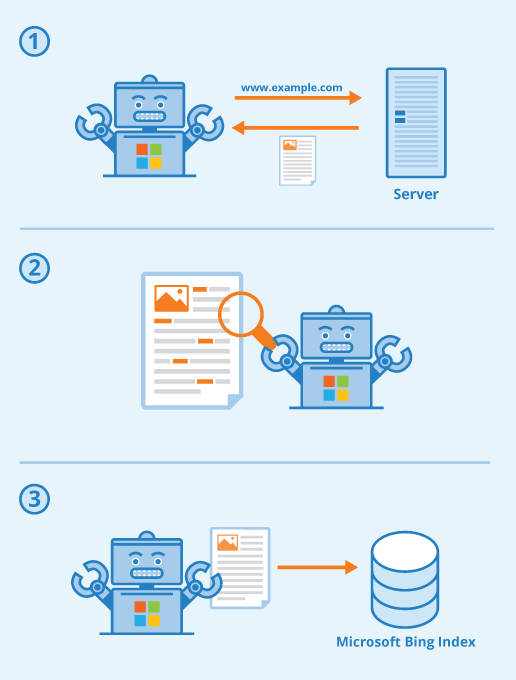
Der Crawler der Suchmaschine Bing ist der sogenannte Bingbot. Er nimmt HTML-Dokumente und Webseiten in sein Verzeichnis, den sogenannten Bing Index, auf, indem er das Web durchsucht. Gibt ein Nutzer dann eine Suchanfrage in die Suchmaschine Bing ein, gibt der Crawler seine gefundenen Ergebnisse in einer sortierten Liste aus.
Der Microsoft Bingbot
Ebenso wie Yahoo gehört die Suchmaschine Bing zum Unternehmen Microsoft. Die Ergebnisse, die der Bingbot liefert, werden in den Suchmaschinen Bing und Yahoo angezeigt, wobei Yahoo zusätzlich den Crawler Slurp nutzt. Der Bingbot durchsucht das World Wide Web und liest, ähnlich dem Google Bot, automatisiert die Inhalte der gefundenen Webseiten aus.
Die Funktionsweise des Bingbots
Um die Funktionsweise des Bingbots zu verstehen, hilft eine kleine Veranschaulichung: Man stelle sich eine Webseite als Baum vor. Dieser Baum hat Wurzeln, die das sogenannte Rootverzeichnis darstellen. Nach oben hin hat dieser Baum verschiedene Äste, die einzelnen Seiten bzw. Hyperlinks der Webseite. Und auch von diesen Ästen verästeln sich weitere Zweige, die Artikel, Bilder oder Dokumente darstellen. Aufgabe des Bingbots ist es nun, diese Verästelungen so schnell wie möglich auszulesen und abzuspeichern. Der Bot versucht, sich seinen Weg vom Root-Verzeichnis aus nach oben zu bahnen und speichert dabei alle Links und Inhalte ab, die er auf seinem Weg vorfindet.
Bewertung und Auslesung der Inhalte
Die Bewertung und die Art und Weise der Auslesung dieser Inhalte ist, ebenso wie beim bekanntesten Suchmaschinencrawler, dem Googlebot, nicht ausreichend bekannt. Zwar sind viele Kriterien der Verfahren bekannt, der genaue Algorithmus hingegen bleibt geheim.
Dem Bingbot Zugriff gewähren
Zwar wird Bing weitaus weniger genutzt als der Marktführer Google, doch ist es trotzdem wichtig, dem Bingbot Zugriff zur Webseite zu ermöglichen. Wenn die Webseite auch im Index von Yahoo und Bing gefunden werden soll, gibt es mehrere Möglichkeiten: Man kann dem Crawler Zugriff gewähren, indem man die Robots.txt entsprechend anpasst oder die IP-Adressen des Bingbots im HTTP Header zulässt. Einzelne Dokumente können durch Metabefehle wie „nofollow“ von diesen Crawlern ausgeschlossen werden.
Vorsicht vor falschen Bingbots
Da es in den vergangenen Jahren vermehrt zu Phishing- und Hackerangriffen kam, bei denen als Bingbot getarnte Fake-Crawler Daten der Nutzer sammelten, bietet Bing eine Verifikation seines Crawlers an. Auch mit den oben genannten Methoden, die dem Bingbot Zugriff auf die Webseite gewähren, lassen sich diese falschen Bingbots ausschließen.
Ähnliche Artikel