Googlebot
Inhaltsverzeichnis
Was ist der Googlebot?
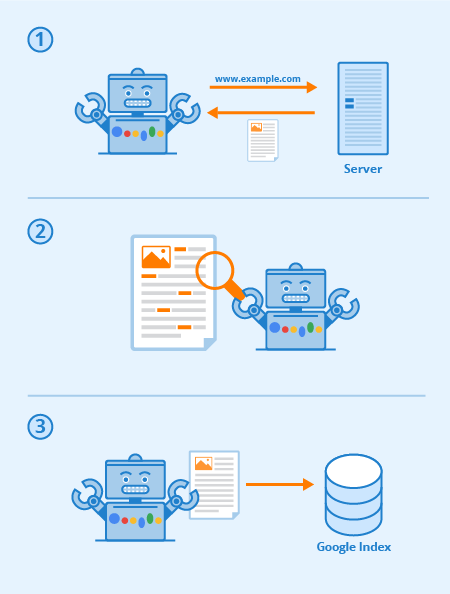
Beim Googlebot handelt es sich um den Crawler der Suchmaschine Google, der kontinuierlich Dokumente aus dem World Wide Web sammelt und diese für den Google Index und die Google Suche zur Verfügung stellt. Der Bot sucht durch ein automatisiertes Verfahren ununterbrochen nach neuen Inhalten im World Wide Web und geht bei diesem Prozess vor wie ein gewöhnlicher Webbrowser: Der Bot sendet eine Anfrage an den zuständigen Webserver, der dann diese Anfrage beantwortet. Danach lädt er eine einzelne Seite herunter, die unter einer einheitlichen URL erreichbar ist und legt diese zunächst im Google-Index ab. Auf diese Weise indexiert der Google-Crawler das gesamte Internet, wobei er auf verteilte und skalierbare Ressourcen zurückgreifen kann, um gleichzeitig Tausende von Seiten zu crawlen.
Wie funktioniert der Googlebot?
Um erfolgreiche Suchmaschinenoptimierung betreiben zu können, ist es wichtig zu verstehen, wie der Googlebot funktioniert. Nachfolgend wird daher dessen Funktionsweise kurz erläutert.
Der Googlebot basiert auf einem hoch entwickelten Algorithmus, welcher in der Lage ist, sämtliche Aufgaben autonom zu erledigen und auf dem Konzept des World Wide Web (WWW) aufbaut. Dieses kann man sich als ein großes Netzwerk von Webseiten (Knoten) und Verbindungen (Hyperlinks) visualisieren. Jeder Knoten wird durch eine URL eindeutig gekennzeichnet und ist durch diese Webadresse erreichbar. Die Hyperlinks auf einer Seite führen dabei auf weitere Unterseiten oder auf Ressourcen auf einer anderen Domain. Der Bot von Google ist in der Lage die Verbindungen (HREF-Links) und die Ressourcen (SRC-Links) eindeutig zu identifizieren und zu analysieren. Wie der Googlebot das gesamte Netz am effektivsten und schnellsten durchsucht, wird durch die eingesetzten Algorithmen genau spezifiziert.
Der Googlebot arbeitet dabei mit unterschiedlichen Techniken. Einerseits kommt das sogenannte Multi-Threading-Verfahren zum Einsatz, das die gleichzeitige Ausführung mehrerer Crawling-Prozesse ermöglicht. Andererseits setzt Google auch Webcrawler ein, die sich auf das Durchsuchen bestimmter thematischer Bereiche konzentrieren, wie beispielsweise das Crawlen des World Wide Web anhand bestimmter Arten von Hyperlinks.
Wie können Webmaster herausfinden, wann der Googlebot auf ihrer Website war?
In der Google Search Console können Seitenbesitzer und Webmaster nachsehen, wann der Googlebot zuletzt ihre Website gecrawlt hat.
1. Schritt
In der Google Search Console muss man zunächst auf den Menüpunkt "Abdeckung" klicken, woraufhin eine Statusübersicht auftaucht, in der Fehler oder Warnungen angezeigt werden. Danach klickt man auf den Reiter "gültig", damit alle fehlerfreien Seiten eingeblendet werden. Unten bei Details wird eine Zeile mit dem Status "gültig" angezeigt, die man anklicken muss.
2. Schritt
Nun wird eine detaillierte Übersicht präsentiert, aus der man ablesen kann, wann der Googlebot zuletzt die Seiten der jeweiligen Webpräsenz besucht hat. Für jede einzelne Webseite wird das genaue Datum des letzten Crawlings angezeigt.
Es kann also durchaus vorkommen, dass die neueste Version einer bestimmten Seite auf der Webpräsenz noch nicht gecrawlt worden ist. In diesem Fall kann man Google den Hinweis geben, dass sich der Content der Seite verändert hat und diese neu indexiert werden sollte.
Wie kann das Crawling einer Website durch den Googlebot blockiert werden?
Webmastern und Seitenbesitzern stehen unterschiedliche Möglichkeiten zur Verfügung, um Webcrawlern Informationen auf ihren Webseiten bereitzustellen oder auch zu verwehren. Jeder Crawler kann durch eine Bezeichnung im HTTP-Header-Feld “User Agent” eindeutig identifiziert werden. Beim Bot von Google lautet diese Bezeichnung "Googlebot", welche von der Hostadresse googlebot.com ausgeht. Diese User Agent Einträge werden in den Logfiles des zuständigen Webservers gespeichert und geben Webmastern detaillierte Informationen darüber, wer Anfragen an den Webserver sendet.
Seitenbetreiber können selbst entscheiden, ob sie das Crawling ihrer Website durch den Googlebot blockieren oder zulassen möchten. Dies kann auf folgende Weise realisiert werden:
- Durch einen disallow Eintrag in der Robots.txt-Datei können ganze Verzeichnisse einer Website vom Crawling ausgeschlossen werden.
- Durch die nofollow Anweisung im Robots Meta Tag einer Webseite wird dem Googlebot mitgeteilt, dass dieser den Links auf dieser Seite nicht folgen soll.
- Durch das “nofollow” Attribut für einzelne interne Links einer Webseite kann sichergestellt werden, dass der Googlebot nur diesen Links nicht folgt (aber den anderen Links auf der Seite schon).
Bedeutung für SEO
Für die Suchmaschinenoptimierung von Websites kommt dem Verständnis der Funktionsweise des Googlebots eine besonders wichtige Rolle zu. Denn um eine Webpräsenz möglichst gut zu positionieren, ist es neben einer sinnvollen Marketing Strategie wichtig zu wissen, wie der Googlebot arbeitet. So ist es beispielsweise empfehlenswert, den Googlebot über die Google Search Console direkt auf neue Seiten einer Website hinzuweisen. Des Weiteren ist es sinnvoll, sogenannte XML-Sitemaps zu erstellen und dem Bot explizit zur Verfügung zu stellen. Diese bieten einen Überblick über alle URLs einer Website und können damit das Crawling beschleunigen. Am wichtigsten ist es jedoch, den Googlebot durch verschiedene Maßnahmen beim Crawling zu steuern, um sicherzustellen, dass dieser alle relevanten Inhalte einer Website findet und nicht unnötig viel Zeit damit verbringt, irrelevante Seiten zu durchsuchen. Mehr Informationen zu diesem Thema gibt es in unserem Blogbeitrag zur Crawl Budget Optimierung.
Weiterführende Links
Ähnliche Artikel
| Über den Autor |
 |