Araña web
Contenido
¿Qué es una araña web o rastreador?
Una araña web, rastreador o crawler en inglés, es un fragmento de software que busca y analiza contenidos en Internet. Es básicamente lo que no se conoce como un bot, es decir, un programa que realiza tareas definidas y repetitivas de forma automática.
Se utiliza principalmente en los motores de búsqueda para analizar e indexar sitios web. Aunque también se emplea para recopilar datos (por ejemplo, para obtener fuentes web o, sobre todo en el ámbito del marketing, reunir direcciones de correo electrónico).
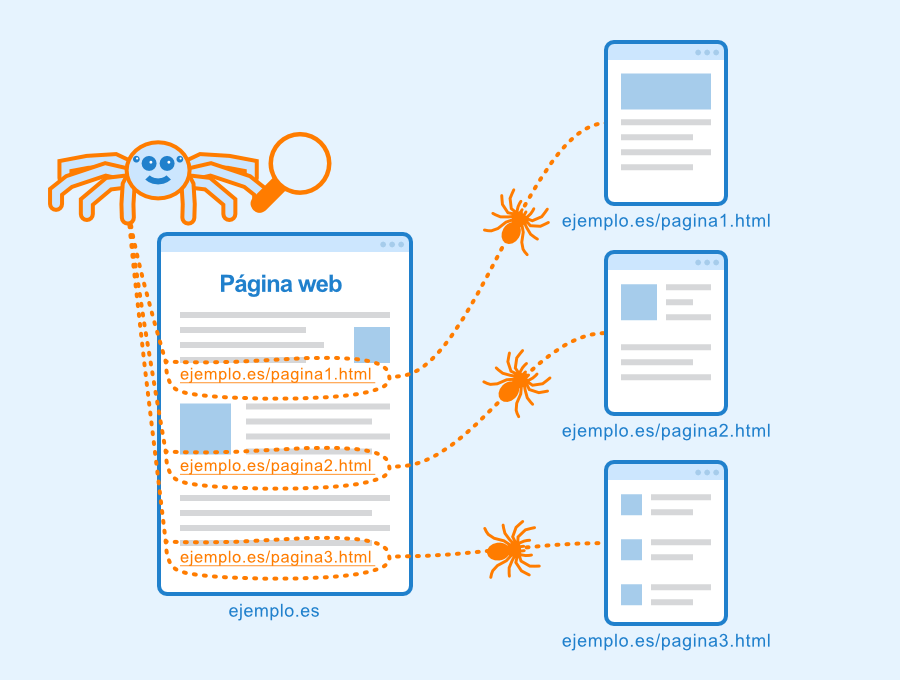
Dado que estos programas van saltando entre links y creando conexiones entre webs, se los conoce como arañas, pues si pudiéramos visualizar su trabajo de manera gráfica, sería como una red de araña.
El primer rastreador web se llamó World Wide Web Wanderer y se empleó en 1993 para medir el crecimiento de Internet. Un año más tarde, se lanzó el primer motor de búsqueda de Internet con el nombre de Webcrawler y tuvo el honor de bautizar a este tipo de programas.
Hoy en día, estos bots son la razón principal por la que la optimización de buscadores (SEO) se encuentra a la vanguardia del marketing online. Por lo tanto, para implementar una estrategia SEO exitosa, hay que saber cómo funcionan estos programas, lo cual explicaremos a continuación.
Funcionamiento de las arañas web
Un rastreador encuentra nuevas páginas web al igual que una usuaria o usuario cuando navega por Internet, a través de hipervínculos o enlaces. Cuando una araña recupera una página, guarda todas las URL que contiene y, a continuación, abre cada una de las URLs guardadas, una por una, para repetir el proceso: analiza y guarda más URLs.
De este modo, los buscadores utilizan bots para encontrar páginas enlazadas en la web. Sin embargo, en la mayoría de los casos, las arañas web no procesan todas las URLs, sino que se limitan a aplicar una selección y, además, en algún momento, el proceso incluso se detiene y se reinicia.
Finalmente, la información recopilada suele evaluarse y almacenarse mediante la indexación para poder encontrarla rápidamente cuando las y los usuarios activen una query o consulta.
Comandos para las arañas web
Se pueden utilizar las normas de exclusión de robots para indicar a las arañas web qué páginas de un sitio web deben ser indexadas y cuáles no. Estas instrucciones se colocan en un archivo llamado robots.txt o también se pueden comunicar a través de meta etiquetas en la cabecera HTML. Sin embargo, hay que tener en cuenta que los rastreadores no siempre siguen estas instrucciones.
¿Dónde se usan los rastreadores?
Las arañas web tienen una amplia gama de aplicaciones y a menudo se ofrecen como una función más de un paquete de software.
Además de indexar la web, lo que es relevante para los motores de búsqueda, estos programas también pueden utilizarse para recopilar información centrada en un tema. Si la búsqueda del rastreador se limita a clasificar un sitio web o un enlace, solo se pueden encontrar en la web, páginas temáticamente importantes.
Por otro lado, también pueden usarse arañas para la minería de datos y la webometría. En la minería de datos, los bots recogen información de grandes bases de datos para identificar tendencias y referencias cruzadas. Mediante el uso de los bots, se pueden crear y evaluar cuáles son las bases de datos más valiosas.
La webometría, por su parte, se ocupa de la investigación de Internet en términos de contenido, propiedades, estructuras y comportamiento de las personas.
Igualmente, existe un tipo especial de rastreador web llamado recolector. Se trata de un programa que busca en la web direcciones de correo electrónico y las recopila, es decir, las almacena en una lista para actividades como el email marketing o el envío de spam.
Optimizar la rastreabilidad de una web para el SEO
SEO Comprobador SEO de rastreabilidad
Comprueba si tu página web es rastreable para las arañas
Para conseguir la máxima capacidad de rastreo y el mejor resultado SEO posible, un sitio web debe tener un buen enlazado interno. Esto es así porque los robots siguen los enlaces para analizar nuevas páginas web y contenidos y, por lo tanto, un enlazado optimizado garantiza que todas las subpáginas importantes puedan ser encontradas por los robots de búsqueda. Si se descubre un contenido de alta calidad en una de estas páginas, es probable que se obtenga una clasificación alta.
Los mapas de sitio XML o HTML también son una solución común para facilitar el trabajo de las arañas web. Contienen la estructura completa de enlaces de un sitio web para que un motor de búsqueda pueda encontrar e indexar fácilmente todas las subpáginas.
Tampoco se debe subestimar el uso correcto de las etiquetas HTML para un buen SEO, pues estas estructuras ayudan a que los robots puedan interpretar el contenido de una página correctamente. Esto incluye, por ejemplo, la utilización estándar de headings o encabezados (h1, h2, h3, etc.), los títulos de los enlaces (title) y las descripciones de las imágenes (alt).
Además, no se debe utilizar contenido Java o Flash. Aunque Google es capaz de rastrear las páginas JavaScript, aún requiere de mucho presupuesto de rastreo. En su lugar, se deben emplear lenguajes del lado del servidor, como PHP o ASP, para generar elementos de navegación y otros componentes del sitio web en HTML. Mientras que el cliente (navegador web o bot) no necesita un plugin para entender e indexar los resultados HTML.
Asimismo, un sitio web moderno ya no debe basarse en frames, sino resolver todos los aspectos del diseño con CSS. Hoy en día las páginas que todavía usan marcos solo se indexan parcialmente y son malinterpretadas por los motores de búsqueda.
Otro aspecto importante para optimizar la rastreabilidad de una web de cara al SEO es que no se debe excluir del rastreo aquellas páginas a indexar, ni en el archivo en robots.txt ni mediante una directiva "noindex" en la meta etiqueta robots. Para comprobar si hay impedimentos de rastreo e indexación, podemos utilizar varias herramientas ofrecidas por los mismos motores. Google, por ejemplo, cuenta con la Search Console para este fin.
Dado que los y las ciberdelincuentes inician cada vez más ataques de bots, las y los webmasters utilizan la llamada protección contra bots. Este sistema de seguridad supervisa el tráfico web, detecta los bots y los bloquea si es necesario. Ahora bien, una protección contra bots mal configurada también puede bloquear los bots de Google, Bing y otros motores de búsqueda, lo que impediría que estos puedan indexar las páginas web.
Por lo tanto, hay que asegurarse de que la protección contra bots verifica la dirección IP del host antes de bloquearlo. De esta manera, se puede detectar si el bot pertenece a Google, Bing u otros motores de búsqueda.
Por último, conviene tener en cuenta que la rastreabilidad también está influenciada por el rendimiento de un sitio web. Si el portal se encuentra en un servidor lento o se ralentiza por problemas técnicos, no suele recibir una buena clasificación en los motores de búsqueda. De hecho, es probable que algunas de las subpáginas no se indexen en absoluto porque los robots saltan cuando una página se carga durante demasiado tiempo.
Por lo tanto, contar con una infraestructura rápida es la base para lograr una optimización SEO que resulte eficaz.
A continuación, vamos a ver todos estos puntos de forma resumida:
- buen enlazado interno.
- Mapa del sitio XML o HTML.
- Uso correcto de las etiquetas HTML para el SEO.
- Diseño sin contenido Java o Flash.
- No incluir frames.
- Comprobar las páginas excluidas por robots.txt y "noindex".
- Configurar la protección contra bots correctamente.
- Infraestructura con rendimiento rápido para un SEO eficaz.
Ampliar conocimientos
- https://www.publisuites.com/blog/arana-web/
- https://www.google.com/intl/es_es/search/howsearchworks/
| Sobre las autoras y autores: |
 |